![The Ultimate Guide to Reduce Speech Latency in AI Calling [Proven]](/content/images/size/w1200/2025/05/Speech-Latency-in-AI.webp)
Speech latency in AI is the delay between when a user speaks and when the system responds. It includes several steps: speech recognition, speech-to-text (STT) conversion, processing by a Large Language Model(LLM), and finally text-to-speech (TTS). Each stage adds milliseconds, and too much delay can make interactions feel robotic. To sound natural, AI systems should aim for a response time between 500 - 800 milliseconds.
Deep dive into our blog on Speech Latency in AI to learn how technologies like speech recognition, STT, and neural networks impact real-time response and what it takes to keep AI fast and natural.
Quick Facts
- AI gives a reply after processing your input. Fast models can begin responding in about 100-150 milliseconds, but more advanced/LLM ones might take a bit longer.

What is latency?
Latency is the delay between when you take an action like clicking a button or speaking and when the system responds. In computer networking, it means how long it takes for data to travel from one place to another, usually in (ms) milliseconds. In systems using machine learning, artificial intelligence, and neural networks, algorithms process your input before giving a response, which can also affect latency.
What is Response Latency?
Response latency is the time it takes between giving a stimulus, like a spoken question or command, and when a person or system starts to respond.
The Four Core Components
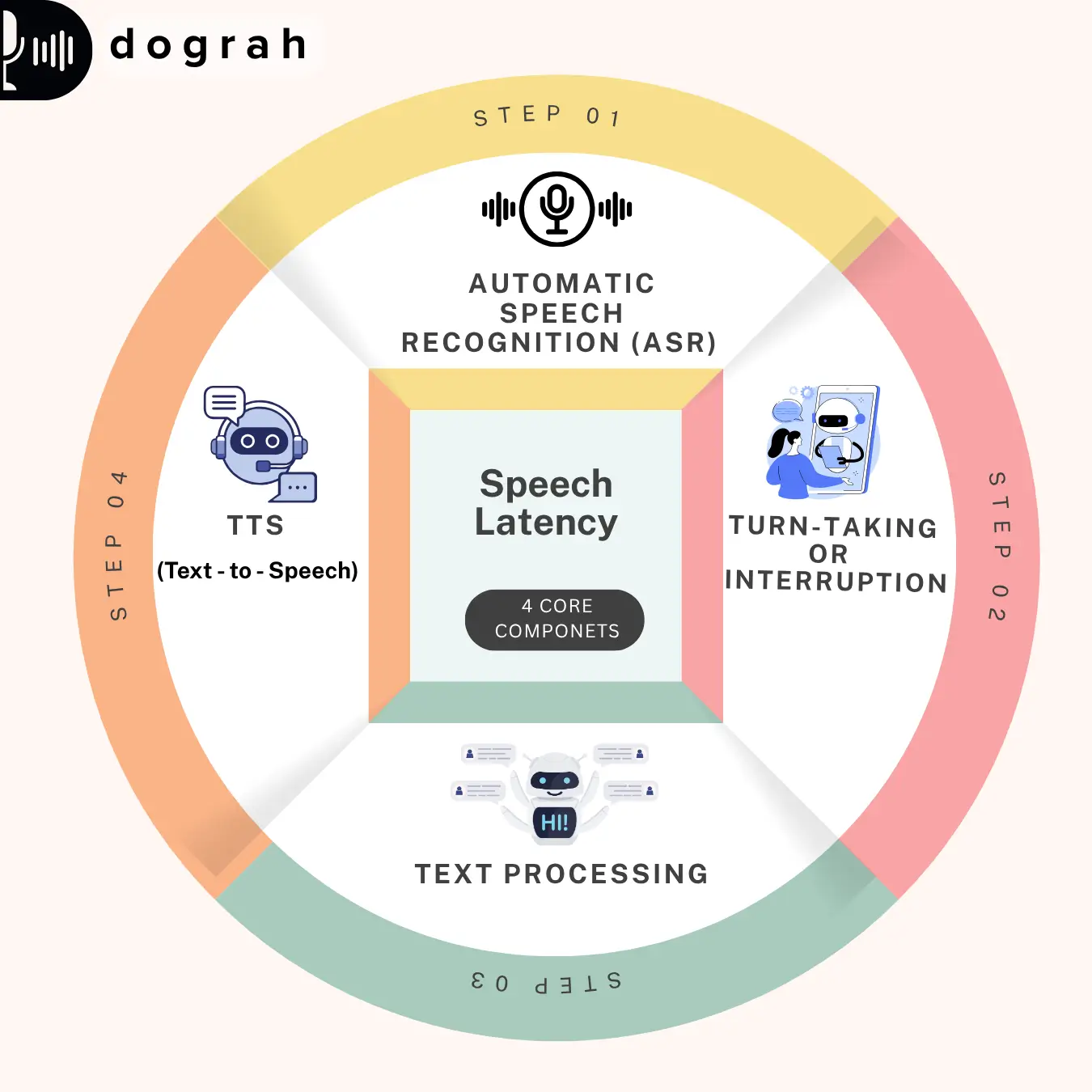
Speech Latency in Voice Ai is the sum of four core components: Automatic Speech Recognition, Turn- Taking/ Interruption, Text Processing, or Text-to-Speech. Each system contributes to responses of the system.
- Automatic Speech Recognition (ASR) - Convert spoken audio into written text, Speech-to-Text (STT). The latency range (100 - 300+ ms) is measured when the user finishes speaking to when text output (Transcription) is ready. The delay in latency varies based on the model and deployment method-cloud-based models.
- Turn Taking/ Interruption - Turn- Taking managed by Voice Activity Detection (VAD), determines when the user has finished speaking and when the AI should respond. VAD detects presence and absence of speech, but turn- taking models analyze pauses, intonation, and context. The latency range (50 - 200ms), slight delay in response make AI feel natural but long pause makes interaction sluggish.
- Text Processing - After the user's speech is transcribed and a turn is detected, the system sends the text to a large language model (LLM) like GPT-4 (232- 320ms) or Gemini Flash (~900ms). The response time depends on how fast the model is, how complex the prompt is, and how much information it needs to consider average latency. Quick models can respond in under 350ms, while larger ones might take up to a second, with the first token's (time to first byte) timing being most important for smooth output.
Note - Latency increases with larger input text, as more data takes longer to process and compute.
- Text- to- Speech - Text-to-speech (TTS) converts the generated text response into spoken audio, and its main latency measure (75 - 300ms) is time to first byte the moment audio playback begins after receiving text. Advanced TTS models like ElevenLabs Flash now achieve this in just 75–135ms, a dramatic improvement from older systems.

Why is Latency Important for Speech Recognition?
Latency plays a key role in creating natural and smooth conversations with AI. If the response time increases beyond a second, the interaction starts to feel slow and less engaging. Human conversational latency is typically under 500 milliseconds, which sets the benchmark for natural dialogue. GPT-4o responds to audio inputs in just 232–320 milliseconds, closely matching human response times of around 150 ms. But most multi modal models perform poorly with reasoning, tool selection and in practical scenarios. Hence most common voice agents use the pipeline of first converting speech to text (STT) and then sending it to an LLM , and then converting the response text to speech (TTS).
How to achieve Low Latency
1. Break Down and Optimize Core Components
To build an effective voice agent, start by breaking down latency across key components: Speech-to-Text (STT), LLM processing, and Text-to-Speech (TTS). STT typically adds 100–300ms and can be optimized with on-device models, streaming APIs, and VAD. LLMs contribute 100 - 500 ms using smaller, faster models with streaming output and caching helps reduce this. TTS latency ranges from 75 - 300 ms, improved by Eleven flash models, WebSockets, and audio caching. Success lies in balancing these layers STT, endpointing, LLM, and voice output while using orchestration and hosting strategies to deliver responsive, natural conversations without obsessing solely over latency.
2. Server Infra Setup
Server setup plays a crucial role in managing latency, with both configuration and location impacting performance. Cloud-based systems can experience delays from network transmission, but placing servers closer to end users helps minimize this. Deploy STT, LLM, and TTS services within the same data center(if open source self deployment feasible) or geographic region to reduce inter-service lag.
3. Multi Region Deployment
To minimize network latency, route requests to the nearest server region. Hence, for global users or critical applications, use multi-region deployments to ensure faster and more reliable performance.
4. Optimize API Payloads
To reduce latency, send only essential data and avoid unnecessary metadata or sub-optimal audio formats. For lower latency and better bandwidth efficiency, choose compressed formats like MP3 or Opus, which reduce file size while maintaining good audio quality. For high quality audio, you may use linear 16 encoded WAV, though it may add latency, especially when fidelity and compatibility are priorities. This format supports multiple sample rates (8000–48000 Hz), which do not impact speed.
5. Reduce Sample Rates
If studio-quality audio isn't required, lowering the sample rate such as from 48kHz to 16kHz can reduce file size and speed up processing, helping improve latency.
6. Text Chunking
When splitting long responses for TTS, it's best to break full sentences into chunks to maintain natural flow and low latency. Splitting mid-sentence can lead to choppy, unnatural audio with inconsistent pitch and tone. While sending and receiving data developers can also experiment with streaming, but it comes with challenges like missing context, which can cause errors in pronunciation, tonality or emphasis. Hence, to improve accuracy during streaming, include a few seconds of prior context to help the model maintain coherence.
7. Implement Async Requests
Instead of waiting for the full audio to generate, you can use asynchronous requests to run transcription and speech synthesis at the same time.
8. End of Speech Prediction
Typically speech pause detection is much faster than end of speech detection. So a brilliant strategy is to assume end of speech (prediction) on speech pause detection. And send user input for LLM response. Meanwhile, wait for an end of speech detection, use the LLM response from earlier - thus saving some precious milliseconds. And when end of speech is not detected, then discard the LLM response- assuming that the user continued their speech.
Building all latency strategies into a system is non-trivial and requires massive development effort. Dograh.com provides an open source platform for building voice agents. It provides pre-built telephony, STT, LLM, TTS integrations. And it takes care of most of the latency problems out of the box.
Challenges in Building Voice AI Agents
1. Low-Latency Media Processing and Transport
Efficient encoding and fast transport of audio data are critical. The system must minimize delays in capturing, encoding, and transmitting audio streams across the network. This involves using real-time codecs, minimizing packet loss, and ensuring consistent media throughput.
2. Fast and Accurate Transcription Model
The ASR (Automatic Speech Recognition) system must quickly and accurately convert speech to text, even under varying accents, noise levels, and speaking speeds. Low-latency and high-accuracy models are essential for natural, responsive interaction.
3. Real-Time Data Pipeline and Buffer Management
Audio needs to be processed in real time with efficient buffering. Poor buffer management can lead to dropped audio or increased latency. Tools like Discord monitor audio pipelines at 20–30 ms intervals to diagnose and resolve issues with audio streaming.
4. Swapping Between Models / Using Multiple Models Together
Depending on the task (e.g., command recognition vs. conversation), agents may need to switch models or run several models concurrently. Coordinating this without introducing latency or conflicts is a technical challenge.
5. External System Integration
Calling external APIs or databases adds unpredictable delays. Managing asynchronous calls and fallback strategies ensures the AI remains responsive while waiting for third-party systems to return results.
6. Phrase Endpointing
Detecting when a user starts and finishes speaking is essential to avoid premature cutoffs or awkward pauses. Good endpointing ensures the AI responds at the right time without interrupting or lagging behind the user.
7. Interruption Handling
The system should support barge-in (user interrupting the AI) and gracefully stop or switch tasks. Handling these interruptions requires real-time intent recognition and robust state management.
8. Echo Cancellation
Especially in full-duplex or open-mic environments, the system must prevent its own output from being picked up by the microphone and transcribed again. Effective acoustic echo cancellation is necessary for clean input.
9. High-Quality, Low-Latency Text-to-Speech (TTS)
The TTS engine must produce natural-sounding speech with minimal delay. Fast models, streaming synthesis, and pre-caching frequently used phrases help reduce TTS latency while maintaining quality.
What are the consequences of latency in speech recognition?
Latency in speech recognition, the time between when a user speaks and when the system responds can seriously impact usability and user satisfaction. When latency is high, interactions feel slow and unnatural, unlike human conversations that respond almost instantly. Delays beyond 200 - 300 milliseconds are noticeable and often lead to user frustration.
How to Measure Latency

Measuring latency in AI, especially in speech-based systems, involves tracking the time it takes for each step of the interaction pipeline. Here's how to do it:
- Total Latency
Total latency is the end-to-end delay from the moment a user speaks to when they hear the system’s response.
Total Latency = Time AI starts speaking - Time user starts speaking
This includes all processing stages: audio capture, STT, AI inference, TTS, and network transit. - Network Latency
Network latency refers to the delay that occurs as data travels between a user and a server. Several factors contribute to this delay. One key factor is the physical location of the server data has to travel farther if the server is located in a different region, increasing latency. Internet speed also plays a crucial role; slower connections result in longer transmission times. - Time to First Byte (TTFB)
Time to First Byte (TTFB) is a crucial network latency metric that tracks how long it takes from the moment a client (like a browser or device) sends a request to a server until the server responds with the first byte of data. A lower TTFB means users or systems start receiving data sooner, which directly improves perceived speed and user experience. - Function Calling
Function calling latency refers to the time taken for an AI system to invoke and receive a response from an external function, such as a database query, third-party API, or internal tool. To measure it, you track the timestamp when the function is called and when the response is received. This latency is critical in AI systems that rely on external tools or plugins, as even a small delay can compound total response time. Optimizing code execution paths and reducing external dependencies can help lower this latency. - Telephony
Telephony latency refers to the delay in transmitting voice data over phone networks, including VoIP systems. As a base, telephony adds around 200ms of latency within the same region. For global calls like from Asia to the USA latency can rise to approximately 500 ms due to longer routing paths this incur latency is geography dependent. - Additional Contributors
Other sources of latency in AI systems include audio format conversions, such as changing MP3 to WAV, which can add processing time. Large model load times also contribute, especially when dealing with complex neural networks that require significant resources to initialize. Large buffer sizes may slow down streaming and increase delays. Additionally, browser or device decoding time can affect how quickly users hear or see the final output, further impacting the overall responsiveness of the system.
How to reduce latency in speech recognition applications?
1. Optimize AI Models
Optimizing AI models is crucial for reducing latency, especially in speech-based interactions where human conversational response time is typically under 500 milliseconds. Swapping between models or using multiple models together can improve performance if done wisely. Choosing the right large language model (LLM) plays a key role model with low time-to-first-token (TTFT). In many systems, LLM latency becomes the main bottleneck after automatic speech recognition (ASR), so selecting a fast and efficient model is essential for achieving smooth, real-time conversations. Also, public LLM Api’s are often unpredictable with latency spilling over to multiple seconds occasionally due to rate limiting or overloaded infra. A commonly used strategy here is to self host open source models like Llama or deepseek.
2. Optimize Network Performance
Optimizing network performance is key to reducing latency in real-time applications like speech recognition. Content Delivery Network (CDNs) help by caching content at various geographically distributed servers, minimizing travel distance. Low-latency protocols like HTTP/2, QUIC, and TCP Fast Open reduce round trips and improve transfer efficiency. Additionally, IPv6 enhances routing efficiency and reduces delays.
3. Improve Text - to - Speech Conversion
Reducing latency in text-to-speech systems is vital for real-time applications like voice assistants and live transcription. Fast models, with a slight quality trade-off, can achieve ~75ms response times. Using streaming or WebSocket endpoints allows playback to begin before the full audio is ready. On-device or local server deployments, along with chunked input and auto-chunking, minimize network delays and parallelize text input and audio output to reduce initial latency.
4. Choose the Right Audio Format
Minimizing latency in speech recognition requires choosing audio formats that balance compression, processing speed, and transmission efficiency. Opus (5–60 ms) is ideal for real-time streaming, VoIP, and WebRTC, while AAC-LD (20–35 ms) suits telephony and hybrid systems. Linear16/WAV offers high accuracy for on-device ASR at 16 kHz. Prioritizing Opus or AAC-LD for networked systems and Linear16/WAV for local processing enables sub-100ms latency with reliable recognition.
5. Cache Repeated Transcriptions
For repeated text-to-speech conversions, caching audio files saves processing time by reusing pre-generated output for identical text. This avoids redundant API calls and speeds up response. Sending small audio chunks to the ASR service enables incremental processing and lowers time-to-first-byte (TTFB). Strategic caching at the architectural, model, or device level can greatly reduce latency while preserving or enhancing recognition accuracy.
6. LLM Latency
LLM latency is the time a large language model takes to generate a response after receiving input. Techniques like model, pipeline, and tensor parallelism distribute workloads across multiple GPUs or servers to speed up processing. Using GPUs, TPUs, and optimized libraries such as TensorRT or Triton further enhances performance. Reducing prompt length and limiting output size also helps lower generation time.
Services / Companies for building Voice AI
1. End to End Voice Agent Builders:
- Dograh: Open source platform for building AI calling agents. Provides a low code interface for building voice agents from scratch without having to bother about all the underlying pieces. Dograh has an inbuilt workflow builder for creating your own voice agents.
- Air AI: Provides an interface for building voice agents. Users may not find the interface so intuitive and pricing is high.
- Retell: Retell also provides a platform for building conversational AI.
2. Speech-to-Text (ASR)
- Deepgram – High-performance real-time ASR with support for custom models and languages.
- Whisper – OpenAI’s open-source ASR model known for multilingual support and robustness in noisy conditions.
- ElevenLabs - The ElevenLabs Speech-to-Text (STT) API, Scribe v1 Model converts spoken audio into text with state-of-the-art accuracy.
3. Large Language Models (LLMs)
- Azure – Offers access to OpenAI and proprietary models through its cloud platform.
- Fireworks – A platform offering hosted access to a variety of LLMs with fast inference.
- Gemini – Google’s multimodal LLM with strong reasoning and integration capabilities.
- OpenAI – Creator of ChatGPT and GPT-4 series, known for high-quality, general-purpose language understanding.
- Llama - LLaMA is Meta’s open-source family of large language models designed for efficient, high-performance natural language understanding and generation.
- Deepseek : DeepSeek is an open-source large language model series focused on code and language tasks, optimized for high performance and reasoning.
4. Text-to-Speech (TTS)
- Azure – Offers neural TTS voices with customization through SSML and voice tuning.
- Deepgram – Recently expanded to include streaming TTS features.
- Eleven Labs – Known for ultra-realistic, emotionally expressive voices.
- PlayHT – Offers fast, high-quality voice synthesis with fine control.
- Cartesia – Focuses on multilingual, edge-optimized TTS solutions.
5. Transport / Media Streaming
- WebSockets – Lightweight protocol ideal for real-time, bidirectional data streams.
- Local Pipes – Optimized for edge deployments and intra-device communication.
- Twilio – Cloud communications platform for voice, video, and messaging.
- Daily WebRTC – Real-time video/audio transport with low-latency APIs.
6. Vision / Multimodal Models
- Gemini Flash 1.5 – Fast, vision-capable variant of Google’s Gemini models.
- GPT-4.0 – OpenAI’s flagship LLM with multimodal capabilities (vision + text).
7. Voice Activity Detection (VAD)
- Silero – Lightweight, accurate open-source VAD that works offline.
- WebRTC VAD – Real-time VAD module built into the WebRTC stack for detecting speech regions.
8. Monitoring / Evaluation and Reinforcement Learning
- OpenPipe – Tool for evaluating LLM outputs, prompt quality, and inference monitoring. Can be used to optimize your agents with Reinforcement Learning.
Other factors in integration
- External System Integration
Connects to databases and APIs for real-time data access and storage. - Fast Voice Responses
Low-latency TTS for smooth, real-time replies. - LLM Function Calling + Streaming TTS
Executes tasks via LLM and streams responses instantly as speech. - Graceful Interruption Handling
Detects and adjusts to user interruptions for natural dialogue.
Dograh.com simplifies all of the above with an open-source, all-in-one platform for building voice agents. It offers pre-built integrations for telephony, speech-to-text (STT), large language models (LLM), and text-to-speech (TTS), while addressing latency challenges seamlessly out of the box.
Getting started with Dograh
Interested in leveraging Dograh for lead generation, cold calling or business automation ? Here’s a streamlined path to getting started, along with direct links to essential resources :
1. Dograh AI: Quick Start Demo
2. Run Docker Command
Download and Start Dograh first startup may take 2-3 mins to download all images
3. Quick Start Instructions
How to Build AI Voice Agent - Step by Step with Dograh
Step by step written guide to building and deploying your first voice AI Agent
- Open Dashboard: Launch http://localhost:3000 on your browser.
- Choose Call Type: Select Inbound or Outbound calling.
- Name Your Bot: Use a short two-word name (e.g., Lead Qualification).
- Describe Use Case: In 5–10 words (e.g., Screen insurance form submissions for purchase intent).
- Launch: Your bot is ready! Open the bot and click Web Call to talk to it.
4. Community & Support

Join Slack Community and discuss issue with Dograh experts :
5. Additional Resource
Related Blog
- Discover the Top AI Communities to Join in 2025 for innovation and collaboration.
- Learn what makes Voice-Enabled AI Workflow Builders Effective in 2025.
- Discover how Making AI Outbound Calls Work: A Technical Guide for Call Centers can streamline automation and boost call efficiency.
- Explore AI Outbound Calling in 2025: What Actually Works Now to learn proven strategies for effective, real-world voice automation.
- See how 24/7 Virtual Receptionist Helps Small Firms Win More Clients by boosting responsiveness and improving customer engagement.
- Learn how How Call Automation Cuts Outbound Calling Costs by 60%: Virtual Assistant Guide can transform your call center’s efficiency and savings.
FAQ's
1. What is the latency of text to speech?
Text-to-speech (TTS) latency typically ranges from 75 to 300 milliseconds, depending on the model and setup. Using streaming, flash models, and caching can significantly reduce time-to-first-byte (TTFB) and overall response time.
2. What is the latency of open AI TTS?
OpenAI's Text-to-Speech (TTS) latency is typically around 150–250 milliseconds, depending on the model and network conditions. Streaming support helps reduce time-to-first-byte, enabling faster voice playback in real-time applications.
3. What is acceptable latency for voice calls?
Acceptable latency for voice calls is typically below 500 milliseconds one-way to maintain natural, real-time conversation. Latency above 500-1000 milliseconds can start to cause noticeable delays and disrupt the flow of dialogue.
4. How do I fix audio latency?
To fix audio latency, optimize your setup by using low-latency hardware, drivers, and audio interfaces, and reduce buffer sizes in software settings. Additionally, use real-time protocols like WebRTC and position servers closer to end users to minimize network delays.
5. How can API latency be reduced?
API latency can be reduced by deploying servers closer to users (geo-distribution), using caching, and optimizing database queries. Enabling keep-alive connections and using efficient protocols like HTTP/2 or gRPC also improves performance.
Was this article helpful?
