Voice agents fail in ways that normal monitoring does not catch. When they fail, users feel it fast: silence, interruptions, wrong actions, and broken flows. Observability lets you see the full call end-to-end and fix issues before users complain.

Shipping voice agents without observability is shipping blind
If you ship a voice agent without observability, you are guessing in production. You will only notice after failures users get angry, hang up, or escalate to a human.
The pain: customer-facing failures you only notice after users complain
- Silence kills momentum first. A user hears silence and says "Hello?" or hangs up before your agent answers.
- Wrong intent is the second killer. ASR (speech-to-text) mishears one word, and now your LLM calls the wrong tool.
- Random regressions are the third killer. You tweak a prompt for "tone" and suddenly the agent stops confirming details or loops.
This is why we started taking observability seriously while building Dograh agents. “In my own builds, agent observability is stricter than regular monitoring because you are watching decisions and actions, not just requests. Capturing full conversation traces plus quality signals has helped us debug real issues.” Founder Dograh
A hard truth from user research is that failures change behavior. A study on voice AI in customer care showed that 75% of users prefer human service over voice AI, 63% fear AI will not handle complicated issues, 49% worry AI will struggle with minor issues, and 45% believe AI cannot deliver personalized experiences. If your agent feels unreliable, users will treat it as unreliable.

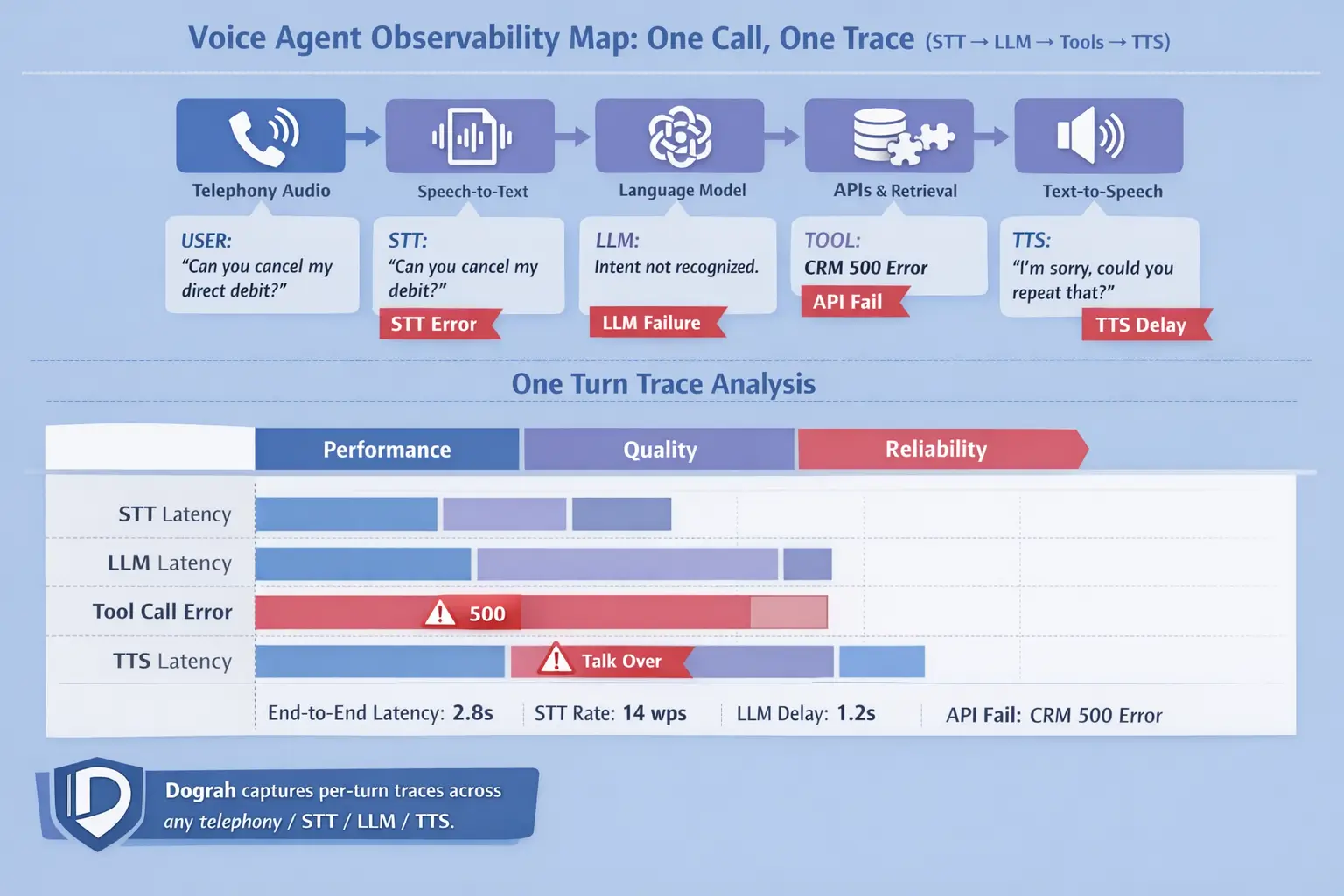
A quick map of the voice stack (telephony -> ASR -> LLM -> tools/RAG -> TTS)
A voice agent is not "one model." It is a pipeline with multiple hops, and each hop can break.
Typical stack:
- Telephony: inbound/outbound call, SIP, call transfer
- ASR (STT): converts audio -> transcript
- LLM: decides what to do and what to say
- Tools / Webhooks: calls your APIs, CRM, ticketing, scheduling, payments
- RAG / Knowledge base: retrieves docs and context
- TTS: converts text -> audio
A single call should be traceable end-to-end with a call_id/session_id. Then every turn (each user speaks -> agent responds) should link to that same ID.
That one simple idea turns debugging from "hours across tabs" into "minutes in one view."
Glossary (key terms)
- Barge-in rate: How often users interrupt the agent while it is speaking, and whether the system detects and responds correctly.
- Time to first audio (TTFA): Time from user stop-speaking to the first audible audio chunk from TTS. This is often what users perceive as "responsiveness."
- Missed tool-call rate: How often the agent should have called a tool (API/webhook/RAG) but did not, leading to wrong or incomplete outcomes.
- Workflow-based evals (node-level evals): Evaluations mapped to parts of your agent workflow (nodes). Each node has its own pass/fail checks and datasets.
- call_id/session_id correlation: A shared identifier that ties telephony, ASR, LLM, tools, RAG, and TTS events into one end-to-end trace.
What breaks in production voice agents
Voice systems often break in ways users can immediately see, even if the root cause only becomes clear after reviewing the full call.
Latency failures: dead air, long pauses, and missed barge-in
Latency is the top reason voice agents feel broken. Even when the content is correct, slow responses lose users.
Common latency failures:
- Dead air: 2-6 seconds of silence after the user speaks
- Long pauses mid-sentence: streaming breaks between tokens or audio chunks
- Missed barge-in: user interrupts, but the agent keeps talking
- Slow tool calls: webhook timeouts block the whole turn
- TTS slow start: TTFA is high even if the text is ready
Concrete examples you will hear in production:
- User: "Hello? Are you there?" (after 3 seconds of silence)
- User talks over the agent, but the agent ignores it and finishes its script anyway
In my experience, when latency spikes, it is hard to pinpoint the cause in a workflow. Is it the LLM API, your backend, or a slow tool call? Without traces, it is guesswork. With traces, it is a timeline.
Speech recognition and audio issues: noisy calls, accents, and wrong transcripts
ASR quality is not stable across conditions. Noise, accent, and line quality can flip intent.
Noise can dramatically increase transcription errors. A speech study comparing multiple STT systems found WER increases sharply with noise intensity. At the worst noise level (SNR ≈ -2 dB), WER jumped by +19.6 percentage points compared with moderate conditions. Under moderate noise (SNR ≈ 3 dB), WER increased by about +6.2 percentage points. This means your agent can be "fine" in demos and fail in real calls.
A realistic mismatch:
- User said: "I need to cancel my plan."
- ASR: "I need to cancel my card."
Now the LLM triggers the wrong tool. From the user's perspective, the agent is not listening.
Accent mismatch is also common. You may need region-specific ASR models, dictionaries, or tuning.
Dograh supports custom dictionaries for business terms, which helps with niche words. Examples: "kay why see" -> "KYC", "HbA1c", "OPD", or "BP high" staying as "BP high."
Tool/RAG failures: missed tool calls, wrong tool, slow tool, wrong knowledge base
Most "smart agent" failures are tool failures. Tool selection is fragile, and errors show up as bad user outcomes.
What breaks:
- Tool not called when it should be (missed tool-call)
- Wrong tool called (wrong endpoint for the user request)
- Wrong parameters (date formats, IDs, missing required fields)
- Webhook timeout or retry storms
- RAG retrieval returns irrelevant docs
- Wrong knowledge base or index used
What you must be able to answer in observability:
- Which user utterance triggered the tool call?
- What arguments were passed?
- Did it succeed?
- What did the tool return?
- Was the response grounded in retrieved docs?
Without this, "the bot said something wrong" becomes difficult to debug.
Prompt and workflow regressions: small changes that break real calls
Voice agents require constant prompt iteration. But small changes can break real calls.
Common regressions:
- Tone shifts to something that sounds rude or robotic
- Missing confirmations ("Did I get that right?" disappears)
- Over-talking (agent speaks too long, invites interruptions)
- Refusal loops ("I cannot help with that" repeated)
- Tool calls stop happening because the prompt changed format expectations
In workflow systems (like Dograh), each node can regress independently. A "handoff node" may be fine while a "billing node" starts looping after one prompt tweak.
This is where versioning matters. You should log prompt versions per node, tied to traces and eval results.
Why normal APM and logs miss voice-agent issues
APM (Application Performance Monitoring) focuses on servers but Voice agents are a distributed, multi-modal user experience.
Scattered data problem: audio in one place, transcripts in another, tools elsewhere
Voice data usually lives in separate systems:
- Telephony provider call logs
- ASR transcripts and confidence scores
- LLM request/response logs
- Tool/webhook logs in your backend
- RAG retrieval logs in vector DBs
- Business KPIs in analytics tools
When something fails, engineers jump between tabs. They correlate timestamps manually. This is slow and error-prone.
A unified approach uses call_id/session_id correlation everywhere. Every log line, span, and evaluation should link back to the same ID.
One community perspective notes the usefulness of "sessions for full conversations, traces for individual exchanges, spans for specific steps like LLM calls or tool usage," plus continuous evals on production logs.
Stochastic outputs and turn-by-turn UX: why debugging is not like normal APIs
Voice agent debugging is not like debugging a payment API. LLM outputs change, and user timing changes.
Key differences:
- Stochastic behavior: same input can yield different outputs
- Stateful calls: each turn depends on previous turns
- Interruptions: barge-in changes the flow
- Quality signals: transcript confidence, word rate, noise, silence
A discussion on observability vs interpretability on Reddit. observability is not interpretability. A useful framing is: observability tells you what happened, interpretability tells you why the model "decided" that way. Traces show prompts, retrieved context, and outputs, but the internal decision process remains opaque.
What observability must include for voice: traces + transcripts + audio + evals
Voice observability needs more than logs. It needs linked artifacts and quality checks.
Minimum set:
- Distributed traces across telephony -> ASR -> LLM -> tools/RAG -> TTS
- Structured per-turn logs (not only per-request)
- Links to audio clips (input and output)
- Transcript versions and ASR confidence
- Prompt and workflow node versioning
- Tool-call payloads + responses + status
- RAG docs/KB IDs used per answer
- Evaluation results tied to the same trace/call IDs
I agree with IBM's position that partial visibility creates blind spots in agent systems, especially when several services and vendors are involved.
Chris Farrell (VP Automations, IBM) summarizes it well: "Observability enables early detection before failures affect users, which is critical for AI agents operating autonomously."
A practical observability framework for voice agents
Good voice observability is simple in concept. You measure each turn, and you connect the whole call.
The must-track metrics (with simple targets you can start with)
Start with a small set that covers latency, speech quality, and success. Then add depth once you have stable instrumentation.
Latency and responsiveness
- End-to-end turn latency (user end-of-speech -> agent starts speaking)
Starter target: keep p95 under ~1.5-2.5s (use-case dependent)
- Per-stage latency:
> ASR latency
> LLM latency (TTFT if streaming)
> Tool latency (including retries)
> TTS latency and TTFA
- Dead-air incident rate (silence > X seconds)
Speech quality signals
- ASR confidence trend (per language/region)
- STT word rate (useful proxy when confidence is unreliable)
- WER if you can measure it, or WER proxies (human audits on sampled calls)
- Background noise signals if available
Agent action quality
- Tool success rate
- Starter target: tool error rate <1-2%
- Missed tool-call rate (agent answered without needed tool)
- Wrong tool-call rate (called tool but incorrect)
- Fallback rate ("I did not get that" / "Let me transfer you")
Conversation success
- Containment rate (resolved without human)
- Escalation/handoff rate
- Repeat question rate (agent asks the same thing again)
- Hangup rate after dead air or refusal
What is per-turn logging (and why it beats request/response logs for voice)?
Per-turn logging means you log each conversational turn as a first-class event. A "turn" is: user speaks -> ASR transcript -> agent decides -> tools/RAG -> agent speaks.
This beats request/response logs because voice is not a single request. It is a sequence where timing, interruptions, and partial outputs matter.
In practice, per-turn logging gives you:
- A replayable story of what happened in the call
- The ability to compare "what the user said" vs "what the system heard"
- A clean unit for metrics (turn latency, ASR confidence, tool success)
- A stable unit for evaluations (per node or per task within the workflow)
Without per-turn logs, you end up with fragments: a telephony log here, a tool log there, and no single record that says "Turn 7 failed because STT misheard 'address' as 'interest'."
Per-turn logging schema: what to capture every time the user speaks
Capture a consistent schema. It makes dashboards, debugging, and eval pipelines much easier.
Per-turn checklist:
- call_id / session_id
- turn_id (monotonic)
- Timestamps:
> user_audio_start, user_audio_end
> asr_start/end
> llm_start/end
> tool_start/end (per tool)
> tts_start/end
> first_token_time, TTFA
- Audio metadata:
> input audio duration
> codecs / sample rate (if relevant)
> links to stored audio clips (secure)
- ASR fields:
> ASR provider + model
> transcript text
> confidence score(s)
> language detected
> word timings (if available)
- LLM fields (redacted as needed):
> model name
> prompt template ID + version
> workflow node name (Dograh node)
> system + developer prompt versions (hashed)
> response text
> token usage + cost estimate
- Tools:
> tool name
> args (structured JSON; redact PII)
> status (success/fail/timeout)
> latency
> response summary (redacted)
- RAG:
> KB/index ID
> retrieved doc IDs + scores
> chunk IDs
- Voice output:
> TTS provider + voice
> output audio duration
- UX events:
> barge-in detected (yes/no)
> barge-in handled correctly (yes/no)
> silence detected
- Outcome labels:
> contained / escalated
> task completed
> user sentiment signals if you track them (carefully)
If you implement just this, you are already ahead of most teams.
Conversation success signals: from "it spoke" to "it solved the problem"
A 200 OK is not success in voice. Success is: the user got the outcome they wanted.
Think in layers:
- Infra success: requests did not error
- Agent success: the agent selected the right action and response
- UX success: user did not repeat themselves or get frustrated
- Business success: task completed, appointment booked, payment taken, ticket created
Signals that matter:
- Containment vs escalation
- Repeated questions (user asks the same thing again)
- Silence and hangups
- Tool-confirmed completions (webhook returned order_cancelled=true)
Voice observability also connects to customer sentiment. When failures rise, complaints rise, and users avoid the agent. The customer care study numbers reflect that trust gap.
Case study: a real incident (UK voice bot) and how traces fixed it
This is what a real incident looks like. It shows why prompt maturity alone is not enough.
Timeline across the stack: what happened from STT to TTS
We were building a UK voice bot. Prompting was mature and the infrastructure looked stable.
Still, the bot underperformed in production. Users escalated more than expected and many calls felt "off."
We pulled traces for failing calls and saw two issues:
- STT was struggling with British accent patterns The transcript mismatches were driving wrong tool calls and wrong confirmations.
- TTS latency was above average TTFA was high, leading to perceived dead air.
The fix was not "rewrite prompts." We changed the ASR model to one that handled the accent better, and we moved TTS to a server closer to the British Isles to reduce latency.
End-to-end tracing matters because it tells you which hop is broken.
Exact user lines + what the system heard (example transcript mismatch)
Here are realistic examples of how meaning shifts:
- User said: "I'd like to change my address."
- ASR: "I'd like to change my interest."
- Outcome: LLM picked a profile-preferences tool instead of address update.
- User said: "Can you transfer me to billing?"
- ASR: "Can you cancel my billing?"
- Outcome: Agent tried to cancel a plan instead of handoff.
- User said: "I need to speak to an agent, please."
- ASR: "I need to speak to Asia, please."
- Outcome: Agent asked irrelevant clarification questions, user hung up.
Once you see these mismatches in traces, the fix path becomes clear: ASR tuning, dictionary support, or model/provider changes.
Proof points to include in your own write-up (MTTR, p95 latency, error rates)
Even early, track and report proof points. They keep teams honest and make improvements visible.
Starter proof points:
- p95 end-to-end turn latency before/after
- p95 per-stage latency (ASR, LLM, tools, TTS) before/after
- Dead-air incidents per 1,000 turns
- Tool timeout rate and retry rate
- Escalation rate before/after
- MTTR improvements once unified traces are live
As you scale, add volume context. For example: "We analyzed X thousand calls this week," then later "millions of calls."
LLM observability and evaluation: how to build eval sets from real calls
Observability tells you what failed. Evaluation prevents the same failure from shipping again.
Why evals are harder in voice: each turn depends on previous turns
Voice evals are not like single-turn chat evals. Context and timing matter.
A 20-turn call has compounding dependencies:
- Turn 12 depends on the state set at turn 3
- A small ASR error at turn 4 can derail the rest of the call
- Users interrupt, and the agent must adapt
So you need eval sets built from real calls. And you must keep those sets updated as production changes.
Research also supports this. A Stanford paper argues that evaluation data quality directly impacts model reliability, and teams need systematic dataset creation balancing coverage, realism, and maintainability.
Workflow-based evals (Dograh-style nodes): map evals to parts of the agent
The simplest way to scale voice evals is to map them to workflow nodes. This is how we approach it in Dograh-style systems.
Instead of "one eval suite for the whole agent," you build:
- Node evals for greeting and routing
- Node evals for billing actions
- Node evals for RAG-based FAQ answers
- Node evals for escalation/handoff
Then you label failures per node:
- STT fail (bad transcript)
- Wrong tool call (wrong endpoint)
- Missed tool call (no endpoint called)
- Wrong KB used (retrieval source mismatch)
- Bad response style (too long, no confirmation, unsafe phrasing)
This structure is practical for iteration. When you change one node prompt, you run that node's eval set first.
What is an eval gate loop for prompt changes?
An eval gate loop is a release process: you only ship prompt changes if evals pass. It is the difference between prompt tweaking and prompt engineering with discipline.
A simple eval gate loop looks like this:
- Collect real calls from production traces
- Add representative turns to eval sets (by workflow node)
- Run evals after each prompt tweak
- Compare pass rates and regression deltas
- Ship only if the change passes thresholds
In voice, include latency budgets in the gate. A prompt that increases tool calls or verbosity may raise turn latency and cause dead air.
Checks to include in early gates:
- Tool-call correctness (right tool + right args)
- Response format and confirmation behavior
- RAG grounding (answer supported by retrieved docs)
- Safety and PII redaction behavior
- Latency budget (p95 or max per turn for test calls)
How observability connects to evaluation (LLM observability and evaluation)
Observability and evaluation should share the same IDs and lineage. That is what makes fixes repeatable.
Observability gives you:
- The trace and the failing examples
- The prompt versions and tool payloads that caused the failure
- The exact conditions (accent, noise, latency spikes)
Evaluation gives you:
- A regression barrier so the same issue does not reappear
- A measurable way to compare prompts and workflows
- A system for ongoing reliability
Evaluation survey found that production-derived test cases improved model performance on real-world tasks by 34% compared to synthetic-only datasets. That matches what most teams learn the hard way.
Best practice: link eval results back to:
- call_id / trace_id
- workflow node
- prompt version
- model version
- tool versions (API schema changes matter too)
Tooling and setup: open standards, open source options, and how to start fast
You do not need vendor lock-in to get strong observability. You need standards, consistent IDs, and a simple storage strategy.
Practical setup with OpenTelemetry + session IDs (no vendor lock-in)
A clean setup can be done in days, not months. Keep it boring and repeatable.
High-level steps:
- Define identifiers
- Generate call_id at call start
- Generate turn_id per user utterance
- Propagate context everywhere
- Include IDs in headers for tools/webhooks
- Include IDs in internal queues and events
- Emit traces (spans)
- Telephony connect span
- ASR span
- LLM span
- Tool and RAG spans
- TTS span
- Emit structured logs per turn
- Use the schema from earlier
- Redact PII and secrets
- Store audio securely
- Save input/output clips
- Store only links in logs/traces
- Apply retention policies
- Build a single trace view
- Trace timeline + per-stage breakdown
- Click from a span to logs and audio
OpenTelemetry is a strong base because it standardizes collection of traces, metrics, and logs. You can start with the OpenTelemetry project and export to your chosen backend.
LLM observability tools: what features to look for
Choose tools by capability, not branding. For voice, these features matter most:
- Session/call correlation for full conversations
- Prompt and workflow version tracking
- Tool-call visibility (args, responses, errors)
- RAG visibility (docs used, scores, KB ID)
- Redaction and access controls
- Eval management (datasets, runs, pass/fail)
- Dashboards for latency, quality, success
- Alerting hooks (Slack, PagerDuty)
- Export APIs (so you can move data later)
If you want an open-source LLM observability layer, Langfuse is often used for tracing and eval workflows, and it can integrate with OTel conventions.
LLM observability open source: a simple stack you can self-host
You can build a solid self-hosted stack with standard parts. Keep it modular.
Common architecture:
- Collection: OpenTelemetry SDKs + OTel Collector
- Tracing backend: Jaeger for trace visualization
- Metrics: Prometheus for scraping and storage and Grafana for dashboards
- Logs: Any structured log store you already use (keep schema consistent)
- LLM tracing + eval layer (optional): Langfuse for LLM spans, prompt versions, and evaluation runs
- Eval runner: A simple job system that replays stored turns and scores outputsv
This keeps you flexible and avoids lock-in. It also fits Dograh's open-source-first direction.
Prerequisites (so the rest of this guide works)
You need a few basics before observability becomes useful. These are simple but non-negotiable.
- A stable concept of turns in your voice runtime
- A unique call_id/session_id per call
- A place to store:
- structured logs
- traces
- audio clips (secure)
- PII handling rules (redaction, retention, access control)
- Ownership: someone responsible for dashboards and alert hygiene
Dograh is built to integrate with many telephony/STT/LLM/TTS providers, so these prerequisites are mostly about discipline and consistent IDs, not vendor choice.
Closing: observability is the control surface for voice agents
Voice agents are fragile because they are multi-hop systems with human timing. If you cannot trace a call end-to-end, you will ship regressions repeatedly.
Observability plus evals is the practical loop:
- Traces show what failed across ASR -> LLM -> tools/RAG -> TTS
- Evals stop the same failure from returning after prompt changes
My view: if you are serious about voice UX, make observability non-optional and budget time for it the same way you budget time for ASR and prompts. Teams that skip it pay for it later in escalations, refunds, and churn.
If you are building with Dograh, treat observability as part of the workflow. Instrument nodes, track prompt versions, and build node-level eval sets from real calls.
FAQ's
1. What are the 4 pillars of observability ?
The four pillars of observability are logs, metrics, traces, and events. In voice AI, you need all four because failures can happen at many hops, telephony, speech-to-text (STT), the LLM, tool calls, retrieval (RAG), and text-to-speech (TTS).
2. What is observability in AI voice agents ?
Observability in AI voice agents means having end-to-end visibility into every call turn, what the user said, what STT heard (and missed), how the LLM reasoned and routed, which tools/APIs were called with what payloads, what knowledge was retrieved, what TTS spoke back, and the latency at each step.
3. How do you debug latency issues in a voice agent using observability traces ?
To debug latency in a voice agent, you need turn-by-turn traces that break the call into clear spans: telephony connect time, STT processing, LLM response time, tool/RAG time, and TTS time (including time-to-first-byte).
4. How can you create and maintain evaluation (eval) sets for voice agents without constant regressions?
Voice-agent evals are hard because every conversation has many turns, and each turn depends on prior context—so the possible paths feel endless. The practical approach is to build eval sets from real calls and map them to parts of your workflow (for example, different nodes in a Dograh flow: greeting, identity check, scheduling, payment, escalation).
5. What should you track per voice-agent turn to catch failures before users hang up?
A practical per-turn checklist: turn latency (with STT/LLM/TTS breakdown), STT quality flags (low confidence, abnormal word rate), tool-call health (failures or missed triggers), knowledge retrieval signals (docs used or retrieval failures), and outcome events like barge-ins, re-prompts, or hangups after pauses.
Was this article helpful?
