
You can usually tell within a few seconds whether a voice agent was built well. The replies come a beat too late, or it talks over you, or the voice is flat enough that you start speaking slower without meaning to. None of that is about how smart the agent is. It comes down to how fast it responds and how well it handles the natural back and forth of a conversation. Both of those are shaped by the speech models you run and the orchestration layer underneath them.
So we're happy to share that Smallest AI's speech models are now available in Dograh. This post is about why it matters if you care about building agents people actually enjoy talking to.
Where conversations actually break down
A voice agent runs a simple loop. You say something, it gets transcribed into text, an LLM reads that text and decides on a reply, and a text-to-speech model turns that reply back into audio. We call this a cascade pipeline. Every hop in the chain adds a little delay, and if any single step is slow, the whole conversation feels sluggish.
Latency is only part of the problem though. The harder bit is timing. The agent has to figure out when you've actually finished talking. Cut in too early and it interrupts you. Wait too long and there's a dead pause before it answers. Real people trail off mid-sentence to think, and a good agent shouldn't treat every short silence as its cue to start talking.
This is turn detection and Dograh gives you two ways to handle it. The default is transcription based, which ends the turn once the transcript looks like a finished thought. There's also a smart turn analyzer that does a better job reading natural pauses in speech. You can switch between them in the workflow settings under the gear icon, in the detection strategy dropdown.
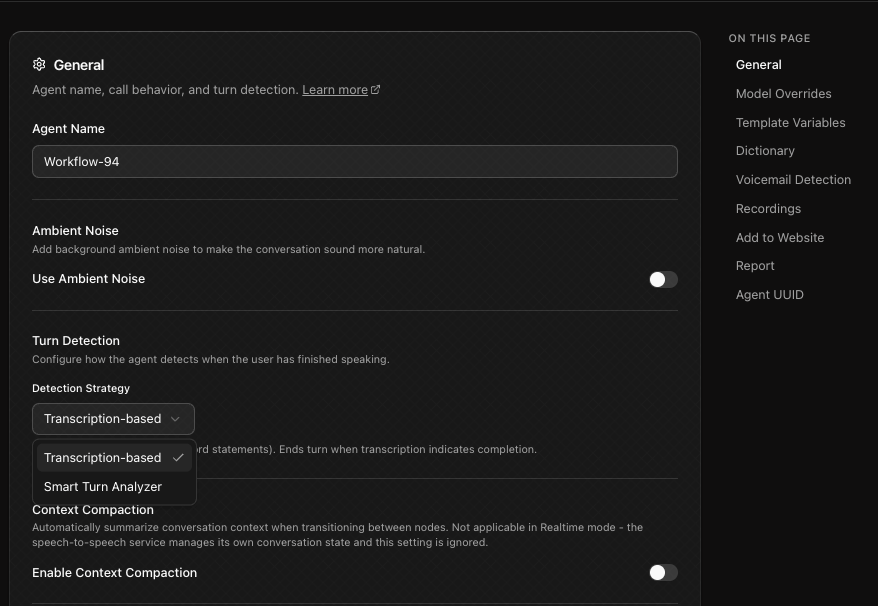
Then there are interruptions. If someone jumps in while the agent is mid-sentence, it should stop and listen instead of plowing ahead with its script. Doing that well depends on fast and accurate Voice Activity Detection (VAD) and fast streaming transcription, so the system notices the interruption almost immediately. This is where VAD engine & the speech models carry most of the load. Quicker transcription means the agent hears you sooner. Quicker speech generation means less gap before it replies. Both feed straight into how natural the whole thing feels.
Smallest AI is now available in Dograh
Smallest's models are built for exactly this kind of real-time work.
Lightning v3.1 is their low-latency text-to-speech model, with 217 voices across 12 languages and streaming output tuned for live conversation. If you want higher fidelity, Lightning v3.1 Pro gives you a premium voice pool with American, British, and Indian accents at 44.1 kHz. On the listening side, Pulse is their streaming speech-to-text model built for low-latency recognition, so your agent understands what was said with very little delay.
Run those together and you get the responsiveness that makes turn-taking and interruptions feel right. The agent hears faster and speaks faster, and the exchange stops feeling like two people on walkie-talkies. Smallest is also SOC 2, GDPR, and HIPAA compliant, which matters a lot once you start putting these agents in front of real customers in regulated industries.
Setting up Smallest in Dograh
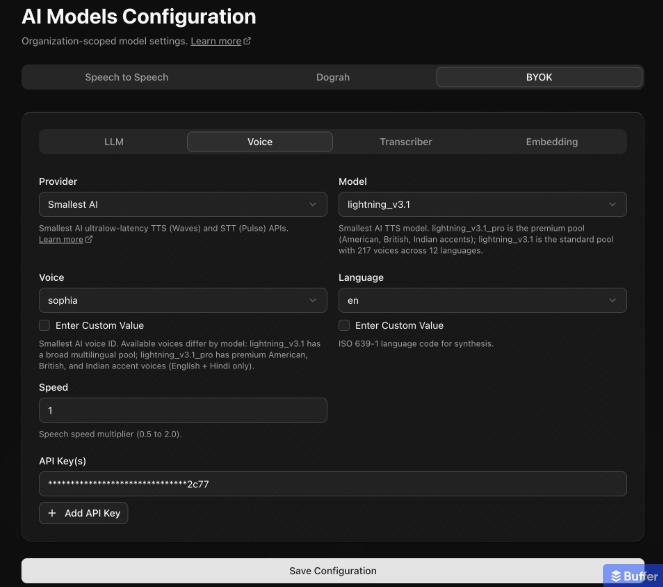
Configuration lives in the models section in the left sidebar. Open it and head to the BYOK tab, where you'll find separate settings for the LLM, voice, transcriber, and embedding.
For voice, pick Smallest AI as the provider, choose Lightning v3.1 or the Pro pool, select a voice and language, set the speed, and paste in your Smallest API key. For the transcriber, select Smallest AI and Pulse is chosen for you automatically. Set your language and that part is done. The whole thing takes a few minutes, and your agent is running on Smallest's stack right after.
Why we don't lock you into a speech provider
Here's something we feel strongly about at Dograh. The orchestration layer, the part that wires your whole agent together, should never get to decide which speech models you're allowed to use. That choice is yours, and it shifts depending on what you're building. A debt collection agent and a healthcare receptionist have very different needs around voice, accent, language, and compliance. You should be able to pick the right model for each one without tearing down and rebuilding everything else. Most closed platforms don't give you that room and if compliance means you need to self-host, you're often stuck.
Dograh is open-source and self-hostable, so you decide where it runs and where your data goes. You bring your own models across speech-to-text, text-to-speech, and the LLM, and you swap them whenever a use case calls for something different. Smallest is a strong option in that lineup. The point is that you get to choose it, rather than have it handed to you as the only thing on the menu.
Try it yourself
The fastest way to hear what Lightning and Pulse sound like in a real agent is to sign up on Dograh and wire them in. It takes a couple of minutes in the models section, and you'll have a working voice agent running on Smallest's speech stack to test against your own use case.

