Written By: Alejo Pijuan
Voice AI quickly reminds you to stay realistic.
On paper, the recipe looks simple: speech-to-text (STT) > a language model (LLM) > text-to-speech (TTS). In practice, once the agent starts taking real customer calls, you realize the simplicity disappears the moment the phone rings.
I've built voice agents across inbound reception, intake, and speed-to-lead. And it was one of the most counterintuitive decisions my team and I made and we still feel good about this:
We routinely choose the higher-quality, slower model when it matters.
Not because we don't care about latency. We do. But in production voice systems, failures compound, and the time you save with a cheaper or smaller model often gets paid back (with interest) in bot behaviour, debugging, rework, and client frustration.
This post is my playbook: how I got here, how we deliver voice AI reliably, why we focus on law firms, and why we'd rather accept a slightly slower response than ship a fast agent that makes "stupid errors that shouldn't be happening."
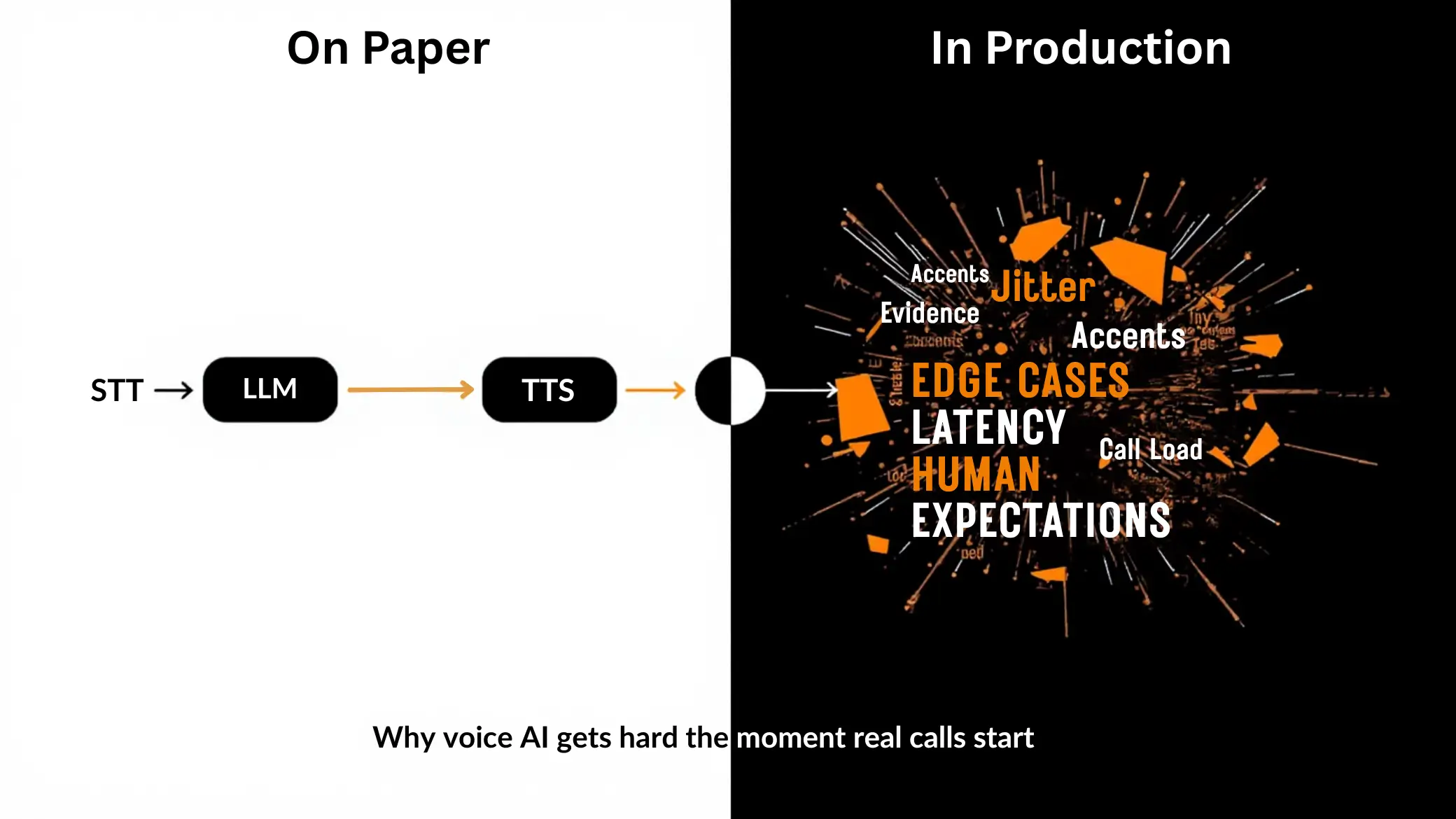
Why I Moved from Corporate Data Science to Building Voice Agents
The moment voice interfaces felt like "infinite intelligence"
A couple years ago, I got captivated by a simple idea: what if talking became the primary interface to intelligence?
Not typing prompts. Not dashboards. Just speaking.
The first time voice interactions really clicked for me, it didn't feel like a toy. It felt like a shift in how humans could access knowledge and take action. And once I saw that, I couldn't unsee it.
Before voice AI, I worked in corporate data science at large enterprises, consumer behavior, analytics, decision support. The work was interesting, but the friction was constant: long decision cycles, fragmented ownership, and projects killed for reasons unrelated to technical merit.
I watched good work get shelved because priorities shifted or leadership changed. That pushed me toward a different goal: own the outcomes, ship systems, iterate fast.
My earlier obsession with reinforcement learning left me with instincts I still use- experimentation needs measurement, feedback loops beat cleverness, and "shiny" isn't "shippable."
I still love innovation. I still get tempted by new tools. But building voice agents for real businesses trained me to pull myself back and ask: Will this reduce uncertainty, or add it?

How me and my Team deliver Voice Agent Projects: Tools first, Skills and Outcomes second
Our guiding rule: use proven building blocks and avoid extra uncertainty
My team's philosophy is simple: We use proven tools and focus our energy on implementation skill, system design, and outcomes, instead of rebuilding the pipeline.
Could we build more custom infrastructure? Sure. But in client delivery, novelty has a cost: more edge cases, more tuning, more surprises. Most businesses don't want an experiment - they want a system that works on Monday morning.
So we prioritize:
- Reliability over novelty,
- Repeatability over "custom everything,"
- Measurable results over flashy demos.
Small projects vs enterprise work: why the engagement model changes
In smaller projects, voice agents often look like:
- Inbound reception coverage
- Outbound follow-ups
- Speed-to-lead after form fills
- Basic routing and scheduling
These can be delivered quickly because the scope is tight and decision-making is usually clearer.
Enterprise work behaves differently.
For bigger organizations - especially ones with complex call volume and many departments - the technical build is rarely the bottleneck. The bottleneck is alignment, process design, and operational adoption.
That's why our enterprise engagements tend to become long-term relationships. We start with one system, prove value, and then the company sees the rest of the opportunity in its operations.
The audit-first approach: finding the highest-value call paths
When a client doesn't come in with a clear spec, I don't guess. I start with what I call an audit-first approach.
Audit-first approach (call path audit) means I map what's actually happening in the business today, calls, handoffs, drop-offs, missed opportunities and then prioritize automation and augmentation based on ROI and risk.
Here's the framework I use:
1. Collect reality, not assumptions
- What are the top call reasons?
- Where do calls get dropped?
- Which teams are overloaded?
2. Map call paths end-to-end
- Identify decision points, transfers, and required data capture.
3. Quantify impact
- Missed calls > missed revenue
- Slow response > lost conversions
- Bad routing > wasted staff time
4. Rank by Impact x Effort
- High impact, low effort goes first.
- High impact, high effort becomes a roadmap item.
5. Phase delivery
Ship something useful quickly.
Add sophistication once the baseline is stable.
What is a call path (and how to map one for voice-agent scoping)?
A call path is the sequence of steps a caller goes through from greeting to resolution.
In practical terms, a call path includes:
- Entry point: inbound number or campaign line
- Intent detection: why the person is calling
- Data capture: what we must collect (name, case type, urgency)
- Routing logic: who should handle it
- Fallbacks: what happens if nobody is available
- Closure: confirmation, next steps, and logging
To map one, I'll often start with a simple diagram:
- Top 5 caller intents
- For each intent: required info + correct destination
- Exceptions: unknown callers, after-hours, urgent scenarios
This mapping is the difference between "we built a bot" and "we built a reliable business system."
Human-first change management: upgrading roles instead of just cutting costs
I'm opinionated about something that gets overlooked in AI conversations: what happens to the people.
It's easy to sell voice agents as "replace receptionists and save money." I think that's short-sighted.
Front-desk staff often have something incredibly valuable: years of direct customer conversation. If you're building a company for the future, you should not throw that away.
I've seen businesses where reception teams were large because call volume demanded it. When automation took over repetitive routing and intake, the best outcome wasn't layoffs - it was upgrading roles:
- Moving experienced staff into higher-skill positions
- Having them supervise edge cases
- Letting them focus on complex conversations where empathy and judgment matter
Voice AI should elevate the team, not just shrink it.

Why I focus on one industry now: Law firms and High-value calls
Specialization wasn't my initial plan. Like many builders, I started broad.
But over time, I realized something: the best voice agents aren't generic - they're operationally embedded. And embedding is easier when you deeply understand one domain.
The three core use cases we keep repeating
In family law, we build the same three systems repeatedly:
1. Inbound intake
- Capture the right info consistently
- Route to the right team
- Reduce missed opportunities and "phone tag"
2. Speed-to-lead for marketing- driven firms
- When firms run ads or strong SEO, leads arrive constantly
- The first responder often wins
- Speed-to-lead systems call or engage prospects quickly, then connect to staff
3. Document- heavy automation opportunities
- Law firms run on documents, forms, invoices, filings
- Even partial automation here can remove hours of admin work
Thinking in suites, not single bots: how one use case unlocks the next
One of the biggest mindset shifts I made was moving from "one bot" thinking to suite thinking.
Most firms begin with a simple pain: We're missing calls. So we start there. But once they see what a stable system can do - consistent intake, better routing, automated follow-ups, they spot gaps that were quietly costing them time and revenue.
That's when the relationship changes:
- Intake connects to CRM
- Routing connects to availability and scheduling
- Follow-ups connect to marketing attribution
- Documents connect to case workflows
One working system becomes the foundation for the next.
What makes this niche practical: value-per-call beats raw call volume
Cost conversations get distorted in voice AI.
In many contexts, cost-per-minute feels high. But in family law, each call can be extremely valuable. If one captured call turns into a signed client, the economics shift.
That's why this niche works:
- Value per call is high
- Missing a call is expensive
- Speed and accuracy materially change outcomes
Contrast that with high-volume, low-margin support environments (like certain BPO-style workflows). There, cost sensitivity is real, and shaving pennies per minute can matter.
In family law, I care far more about this: Did we capture the lead? Did we route correctly? Did the experience feel professional?
The Hardest part is rarely the Bot: Scoping, Leadership alignment and Change requests
People love to ask me, "What's the most complex agent you shipped?"
Sometimes the honest answer is: the complex part wasn't the agent - it was the humans changing their minds.
A complex production reception router
One of the most operationally important systems we've built is what I'd call a production reception router.
Production reception router: an inbound voice system designed to handle real call volume, determine caller needs, check staff availability, route correctly, and gracefully fall back when the ideal destination isn't available.
At a high level, this type of system includes:
- Inbound answering and intent capture
- Basic recognition checks (do we have context on this caller or not)
- Routing to the right team based on intent
- Availability checks for key people
- Transfer logic with safe fallbacks
- Directory-style lookup so callers can reach specific staff
What makes this hard isn't one fancy prompt. It's the combination of:
- Business rules
- Exception handling
- Operational correctness under load
- and the requirement that it feels natural to callers
Why "small changes" are expensive in voice agents
In voice agents, tiny edits are rarely tiny.
Change one line of instruction, tweak one routing phrase, add one new validation question - and you often have to re-evaluate the entire experience.
Why?
- LLM behavior is probabilistic, not deterministic.
- STT introduces noise and ambiguity.
- Voice UX changes ripple through timing, turn-taking, and user expectations.
This is where teams get surprised: a "minor improvement" can trigger a full regression cycle.
What is "change-request tax" in voice agents (why 'small changes' get expensive)?
Change-request tax is the hidden cost of modifying a voice agent after it's already working.
The "tax" comes from the fact that changes require:
- Re-running test suites
- Re-checking edge cases
- Validating transfers and fallbacks
- Confirming the agent still captures required fields
- Listening to real conversations to ensure tone and pacing still work
In other words: you don't just change the bot - you re-certify the system.
My process for preventing endless rebuild loops
To avoid endless iteration spirals, I use delivery discipline:
1. Freeze requirements for a build window
- Not forever. Just long enough to ship.
2. Define acceptance tests upfront
- What must the agent do correctly 95%+ of the time?
- What counts as failure?
3. Make changes go through impact review
- What breaks if we do this?
- What must be re-tested?
4. Schedule iteration windows
- Collect requests during the week
- Batch changes into planned releases
5. Version everything
- Prompts, flows, integrations, and test suites
This is how you keep trust with stakeholders: you move fast, but you don't thrash.
My current voice agent architecture: quality-first choices and practical latency tuning

The standard voice pipeline I use today (STT > LLM > TTS)
Most of what we ship uses a classic pipeline architecture:
1. Telephony layer
- Receives/places calls
- Handles audio streaming and call control
2. STT (speech-to-text)
- Converts caller audio into text
- This step is critical and still imperfect in the real world
3. LLM (reasoning + control)
- Interprets caller intent
- Chooses next action (ask, confirm, transfer, log)
- Produces structured outputs when needed (for CRM updates)
4. Orchestration + integrations
- Connects to business systems (CRM, scheduling, directories)
- Enforces guardrails (required fields, permitted actions)
5. TTS (text-to-speech)
- Speaks back to the caller
- Voice quality affects trust more than many teams realize
That's the technical skeleton. The "muscle" is in the details: prompts, routing policies, and evaluation.
Why I pick a stronger model even when it is slower
Here's the trade-off I've seen repeatedly:
- Smaller models can be faster.
- Stronger models are usually more consistent and less error-prone.
What pushed me to choose quality-first is a pattern I kept watching:
Bad transcripts + weaker reasoning = compounding failures.
If STT is imperfect (and it is), a weaker model is more likely to:
- Misunderstand intent
- Miss important details
- Route incorrectly
- Ask irrelevant questions
- Get "confused" and recover poorly
Then my team spends time patching around basic mistakes, time we could have used to improve the overall system.
So we accepted a principle: We'd rather trade a bit of speed for fewer failures and less engineering thrash.
In practice, that means we often stick with a top-tier general model because:
- it handles messy input better
- it makes fewer "stupid errors"
- it reduces rework
- it protects the client experience
Latency reality: I worry more about spikes than average speed
Latency matters, but latency spikes matter more.
Latency spikes (vs average latency) are sudden slowdowns caused by traffic bursts, provider congestion, or rate limiting. Callers don't experience your average response time; they experience the worst moment.
I'm usually less worried about an extra ~100ms of steady latency and more worried about:
- Occasional multi-second stalls
- Unpredictable delays during peak hours
- Variability that makes the agent feel "broken"
Operationally, the best results I’ve seen come from using provider-level features that keep performance steady under load and avoid worst-case moments. If clients are happy and calls feel natural, I don’t over-engineer latency.
What I am watching next: duplex-style models (and why I am not rushing)
I'm very interested in duplex-style voice models, because they promise a more human turn-taking experience.
But I'm not rushing production workloads into the newest paradigm just because it's exciting. My default posture is: prove maturity first.
What is a duplex-style (full-duplex) voice model, and how does it differ from a pipelined STT > LLM > TTS system?
In a pipelined system:
- the caller speaks
- STT transcribes
- the LLM decides
- TTS speaks
It's sequential.
In a full-duplex model, the system is designed to handle speaking and listening more fluidly, closer to real human conversation. It can potentially:
- interrupt naturally
- backchannel ("mm-hmm," "got it") more smoothly
- reduce the robotic pause between turns
It's promising. But for me, the standard to adopt something new is simple: Does it reduce uncertainty in production, or add it?
Testing and Reliability: How I Ship Voice Agents without guessing
Manual testing is useful, but it cannot be the main safety net
I genuinely enjoy manual testing. I like talking to a new agent and getting a feel for:
- Pacing
- Tone
- How it recovers from confusion
- Whether it sounds like a professional representative of the business
But manual testing has a ceiling:
- it doesn't scale
- it's inconsistent
- it misses edge cases
- it's hard to turn into repeatable evidence
So I treat manual testing as craft. Not as quality assurance.
Automated QA: bot-to-bot test runs and measurable checks
Manual testing is craft, not quality assurance. I enjoy talking to new agents to feel out pacing and recovery, but it doesn't scale and misses edge cases.
For real reliability, we use bot-to-bot test runs-automated conversations where a simulated caller hits the agent across dozens of scenarios, generating pass/fail results and catching regressions.
We measure: correct routing, required fields captured, no hallucinated promises, graceful fallbacks.
Focusing on one industry gives us reusable metrics across clients, intake completeness, transfer accuracy, lead capture rate. When you operate in one vertical, your QA becomes leverage.

Conclusion
Voice AI is finally practical in B2B because it plugs into something every business already has: calls.
But practicality doesn't come from flashy demos. It comes from:
- Mapping call paths correctly
- Choosing reliable building blocks
- Managing change requests with discipline
- Testing with bot-to-bot runs
- and sometimes choosing the slower, higher-quality model because it prevents compounding failures
I don't obsess over shaving every millisecond off average latency. I care whether the system behaves correctly when transcripts are messy, when traffic spikes, when stakeholders change their minds, and when real customers call with real urgency.
If I have to choose, I'll take the agent that sounds professional and routes correctly over the agent that responds faster but creates cleanup work for staff and follow-on calls for clients. Speed is nice; trust is the product.
That's the difference between "we built a voice bot" and "we built production voice infrastructure."
FAQ's
1. How much latency is actually acceptable in a voice agent?
Most callers won’t notice an extra ~100–200ms if responses are steady and natural. What they do notice are sudden multi-second pauses or inconsistent behavior during peak load.
2. What goes wrong when teams optimize too aggressively for speed?
Speed-first systems often compound failures: imperfect transcripts + weaker reasoning lead to misrouted calls, missed intake details, and more manual cleanup for staff.
3. What is a “call path,” and why does it matter so much?
A call path maps every step a caller takes, from greeting to resolution. If you don’t map it explicitly, the agent may sound smart but fail operationally.
4. What is the audit-first approach you mention?
Before building anything, we analyze real call data: top call reasons, drop-offs, routing failures, and missed revenue. Automation decisions are then prioritized by impact and risk, not guesswork.
5. How do you test voice agents reliably before going live?
We use automated bot-to-bot test runs that simulate dozens of call scenarios and produce pass/fail metrics for routing accuracy, intake completeness, and fallback behavior.
