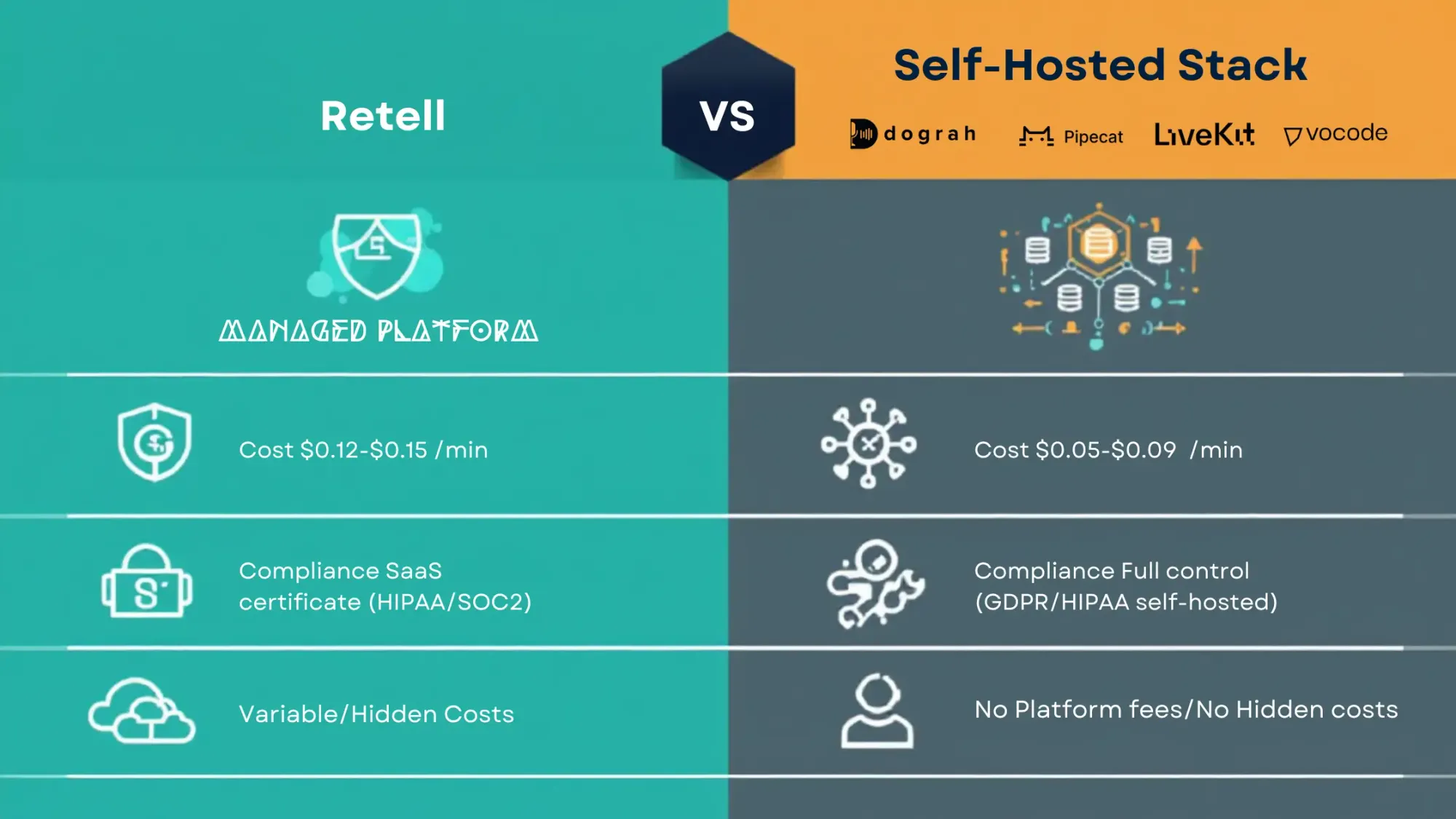
If you are choosing between Retell and a self-hosted stack (Dograh, LiveKit, Pipecat, Vocode), you do not need more feedback. You need a cost model, real cost analysis, and a break-even point. This post provides you, monthly cost breakdown tables of Self-hosted vs Retell.
Self-hosted platform ensures data security and residency by reducing external vendor hops and making it easy to follow privacy and regional data residency norms supported by Dograh OSS.

What This Post Will Answer
You will leave with a cost formula you can realistically budget against, and a clear view of when self-hosting saves money and when it doesn’t.
Comparison Self-hosted: Dograh, LiveKit, Pipecat, Vocode vs Retell
Two paths show up in almost every voice agent project. Both can work. The costs and risks are different.
Path A: Retell hosted platform Retell is a managed voice agent platform. You pay a per-minute platform fee, then usually pay other vendors for telephony and sometimes for models. Pricing starts at $0.07+/min for voice agents and $0.002+/msg for chat agents, but real costs can rise when you add STT/TTS/LLM and telephony items.
Path B: Self-hosted (framework + your infra + your vendors) You run your own orchestration and deployment, using components like:
- Dograh (open source, drag-and-drop builder, self-hostable)
- LiveKit (real-time infrastructure, you can host or use LiveKit Cloud)
- Pipecat / Vocode (open source frameworks for voice pipelines)
With self-hosting, you control data flow, model choice, hosting region, and tooling. You also own uptime and debugging.
A simple cost formula
You will get:
- A TCO formula for Retell and self-hosted
- Scenario tables for 500, 3,000, and 10,000 minutes/month
- A break-even chart approach you can recreate in a spreadsheet
- A place for dev time as a real cost
We also call out concurrency assumptions, because concurrency can change your bill fast.
Table of Contents
- What we used (hands-on notes, real deployments, and quick benchmarks)
- Myths to Ignore before you do the math
- Cost model (TCO): exact line items you must include
- Real cost scenarios: monthly totals (tables you can copy)
- Security and Compliance: when self-hosting is the simplest path
- Developer experience and build speed (time-to-first-call vs long-term control)
- Decision Guide: pick the cheapest + safest option for your team
- FAQ
Hands-on notes, real deployments and quick benchmarks
The numbers here are taken from official websites and real deployments. Reflect realistic ranges, not artificial precision.
From deployments:
- Retell often lands around ~$0.12-$0.15/min excluding telephony in practice, depending on voice and model choices (deployment notes from our projects).
- Self-hosted can often be kept under ~$0.06/min excluding telephony at decent scale when using third-party STT/TTS/LLM plus your own hosting (deployment notes).
- Advanced self-hosting can go below ~$0.02/min, but it is tricky and not what we recommend early (deployment notes).

Glossary (key terms)
- Concurrency tiers (included concurrent calls): The maximum number of calls that can run at the same time under your plan. If you exceed it, you may throttle, queue, or pay more.
- SIP trunk (telephony/SIP): A provider connection that routes phone calls over the internet. It is how your agent sends/receives PSTN calls without being a telecom carrier.
- p95 first-response latency: The time it takes for the agent to produce the first audible response after the call starts, measured at the 95th percentile. p95 captures common worst-case delays.
- Call recording integrity: Whether recordings are complete, correctly linked to call IDs, and reliably stored. It affects debugging, compliance, and dispute handling.
- TCO (Total Cost of Ownership): The full cost including vendor fees, telephony, hosting, monitoring, and people time (build + maintenance + on-call).
Cost model comparison Retell and Self-hosted
Below is the full checklist comparison of Retell and Self-hosted voice agent
Retell cost formula (per-minute + what is included vs not included)
Retell's cost is usually: Retell Monthly Cost = (Retell platform minutes x $/min) + telephony + add-ons + dev time
Common line items:
- Per-minute platform charges (starting at $0.07+/min)
- LLM usage (Ex: GPT 5 $0.04/minute either bundled, marked up, or BYO depending on setup)
- TTS usage (often a large component; Retell's example shows $0.070/min for ElevenLabs TTS
- STT usage
- Branded outbound calls: $0.10 per outbound call
- Telephony (phone numbers + inbound/outbound minutes; often Twilio)
Self-hosted cost formula
Self-hosted Monthly Cost = hosting + model usage + telephony + tooling + dev/ops time
Hidden costs checklist
These are the line items people forget. Each one becomes money or time.
- Telephony phone numbers and per-minute calling
- Call recording storage (and retention policies)
- Retries, dropped calls, and re-dials
- Prompt and tool debugging time
- QA time with real call scripts
- Load testing for concurrency spikes
- Compliance reviews and vendor security questionnaires
- Outages and incident response
- Support delays (waiting days for an answer can block shipping)
Factors That Change Results Including Latency, Concurrency, Model Choice and Outbound Dialing
These are the biggest cost levers. If you optimize only one thing, optimize one of these.
- Minutes/month: the obvious multiplier
- Concurrency: more simultaneous calls means more infra and often higher tiers
- Model choice: LLM and TTS can dominate cost
- Outbound vs inbound: outbound adds dialing costs and sometimes per-call fees (Retell branded outbound adds $0.10 per outbound call)
- Latency targets: lower latency may require more expensive models or co-located servers
- Region placement: placing servers near users can reduce first-response latency (self-hosting gives you more control here)
Real cost scenarios at 500 , 3k and 10k mins
These tables are meant to be copied into a sheet. They include dev time because it is part of TCO.
Scenario table: 500 minutes/month
At this size, build speed dominates. The per-minute delta is usually not the deciding factor.
Assumptions
- Excluding telephony in the base per-minute ranges (telephony added separately)
- Retell real-world platform range: $0.12-$0.15/min excl. telephony
- Self-hosted run-cost range: $0.04-$0.06/min excl. telephony
- Dev time is a one-time build cost spread over a month for comparison
Telephony reference (typical ranges)
- Twilio US inbound: $0.0085-$0.022/min, outbound: $0.013-$0.030/min
Monthly cost table (500 minutes)
At 500 minutes: Pick Retell unless you have a hard requirement for data control or you already have the infrastructure and skills to run this reliably. Self-hosting can be the right call, but it is rarely the cheapest path for an MVP.
Scenario table: 3,000 minutes/month (small business / agency client)
At this size, per-minute fees start to matter. Reliability starts to matter too.
Assumptions
- Retell: $0.12-$0.15/min excl. telephony
- Self-hosted: $0.04-$0.06/min excl. telephony
- Telephony: add separately
- Concurrency: assume 3-10 concurrent calls during peaks
Monthly cost table (3,000 minutes)
From deployments: This is where teams start feeling the Retell bill. It is also where self-hosted starts to look attractive if you can reuse the same platform across clients. If you are an agency, self-hosting becomes a competitive advantage because you stop paying platform markup on every client minute.
Scenario table: 10,000 minutes/month (scale point where break-even often shows)
At this size, platform markup hurts. Self-hosting often wins on run-cost if you do it properly.
We show two self-hosted variants:
- A: BYO cloud STT/TTS/LLM (simpler, common)
- B: Advanced self-hosted models (cheaper per minute, but non-trivial)
Assumptions
- Retell: $0.12-$0.15/min excl. telephony
- Self-hosted A: $0.03-$0.06/min excl. telephony
- Self-hosted B: <$0.02/min excl. telephony but higher complexity
- Monthly cost table (10,000 minutes)
Warning on variant B: you can drive unit cost below $0.02/min, but it is not beginner-friendly. You need expertise in model hosting, GPU orchestration, request queuing, and incident handling. Most teams should start with open source orchestration (like Dograh) while still using third-party STT/TTS/LLM, then migrate pieces later.

Vapi vs Open Source Voice Agents: Which to Choose?
Discover Vapi vs Open-Source voice agents like Dograh, Pipecat, LiveKit, and Vocode to decide the best option for cost, control, and scale.
What Makes Voice Calls Reliable ?
Reliability is what users notice. A voice agent that sounds smart but responds late loses trust fast.
Latency and first response time
A few seconds of silence at the start of a call feels broken. In real deployments, a 3-4 second lag at the beginning can destroy credibility, especially if it persists.
Published benchmarks back the idea that hosted pipelines can be faster at p95:
- Hosted: p95 end-to-end 1.5-2.0s
- Open-source: p95 end-to-end 2.0-3.0s
That gap is not always your framework's fault. It is often:
- region placement
- model cold starts
- network routing
- audio chunk sizes
What is first-response latency in live calls?
First-response latency is the time from "call connected" to the first meaningful audio response. It includes time to start streaming, detect speech, transcribe, generate tokens, and synthesize speech.
Ongoing turn latency is what happens after the call settles. That is the back-and-forth delay during the conversation.
First-response latency matters more for perceived quality. If the agent starts strong, users forgive small delays later.
A practical fix we have used in self-hosted deployments is co-locating servers closer to end users. This can reduce first-response latency, and it is a real advantage when your users are concentrated in specific regions.
Retell vs self-hosted performance trade-offs
Why Retell feels faster early:
- pre-optimized voice settings
- curated defaults
- fewer knobs to misconfigure
Why self-hosted win in long-term:
- you can pick any model and tune aggressively
- you can place servers near your users
- you can remove vendor hops
Self-hosting is not automatically faster. But with the right architecture, it can match hosted latency while giving you more control.
Synthflow vs Open Source Voice Agents: Which to Choose ?
Explore Synthflow vs Open-Source voice agents like Dograh, Pipecat, LiveKit, and Vocode to find the best option for cost, control, and scalability.
Security and compliance
Compliance is often a data-flow problem, not a checkbox problem. Where data travels is usually the hard part.
Data flow and the "extra hop" problem
Each additional vendor in your audio path is another risk surface. That is true even if vendors have strong security programs.
In many proprietary setups, audio, transcripts, and recordings flow through:
- telephony provider
- voice platform vendor
- model vendors (STT/TTS/LLM)
- your application
Self-hosting platfrom like Dograh reduce hops. At minimum, it lets you control what you store, where, and how long.
What is the "extra hop" problem in voice agent data flow?
The "extra hop" problem means your call data passes through an additional third party before it reaches your systems. That third party may see audio streams, transcripts, tool payloads, and metadata.
This matters because it can create:
- extra legal agreements (DPAs)
- extra breach exposure
- extra retention risk
- data residency conflicts
Self-hosting does not remove all vendors. But it can keep orchestration and storage inside your environment, which often simplifies audits.
Example: AI voice agent for healthcare
Healthcare voice flows can include protected health information. That triggers strict access control, logging, and retention rules.
A practical architecture pattern we have used in regulated environments:
- Self-host orchestration and storage
- Encrypt recordings at rest
- Restrict staff access with least privilege
- Implement retention and deletion policies
- Log every access to transcripts and recordings
Even if a platform claims compliance, the extra hop can make internal approval harder. With self-hosting, the data resides on your servers, which often makes privacy controls easier to document and enforce.
Retell AI vs Dograh AI : Which is Best For You in 2025 ?
Retell AI vs Dograh AI in 2025: a clear comparison of costs, features, and use cases to help you choose the right voice AI platform.
Developer experience and build speed
Speed to first call is a business advantage. Long-term control is also a business advantage. You must choose what matters now.
Learning curve reality
Retell is usually faster to ship. You can often get a basic agent running in a few hours because defaults are intuitive and not hidden behind deep configuration.
More configurable platforms can take longer. This is not because they are worse. It is because they expose more choices, and choices require decisions and testing.
How to build an AI voice agent
You can ship with either approach. The difference is who owns the moving parts.
A) Retell setup (fast path)
- Create an agent and define the prompt and tools
- Connect a phone number and call routing
- Add webhooks for your backend actions
- Test with real call scripts and monitor logs
Pricing and add-ons should be checked directly on Retell's pricing page, because the real bill depends on model and voice choices.
B) Self-hosted setup (Dograh / LiveKit / Pipecat / Vocode)
- Choose orchestration: Start with Dograh if you want a visual builder plus self-hosting options (Dograh). Use LiveKit/Pipecat/Vocode if you want framework-level control
- Pick STT/TTS/LLM vendors (or self-host later)
- Connect telephony: Twilio, Plivo, or Telnyx, depending on rates and routing needs
- Deploy and monitor: logs, metrics, recordings, dashboards
- Load test concurrency and failure cases
Dograh is designed to reduce the self-hosted glue work. It supports bring-your-own telephony and models, and it is committed to open source.
Dograh AI slack community let user to connect with developers, founders and professional team dograh offers guidance and fast support.

How to Choose the Most Cost-Effective and Secure Option for Your Team
The cheapest option depends on who they are and what they are building. This should be used as a map.
Solo builder vs 1 Engineer vs Enterprise
This framing is consistent across most serious cost breakdowns. It is also a practical way to choose.
Solo builder / non-technical team
- Best fit: Retell
- Reason: fastest time-to-first-call, fewer infrastructure decisions
One engineer (startup or agency)
- Best fit: start with Retell or Dograh + hosted model vendors
- Reason: ship quickly, then migrate pieces when minutes grow
- If you need flexibility early, Dograh gives open source control without starting from scratch
Enterprise / regulated
- Best fit: self-hosted with Dograh/LiveKit-style control
- Reason: data residency, audit needs, reduced extra-hop risk
- You will still use vendors, but you can reduce scope

Prerequisites (so the cost math is fair)
You cannot compare platforms fairly without these inputs. Collect them before you decide.
- Target regions (US, EU, or both)
- Expected minutes/month and peak concurrency
- Inbound/outbound split
- Recording and retention needs
- Required integrations (CRM, calendar, ticketing)
- A realistic hourly cost for engineering and operations
Where Dograh fits (and why we built it)
Self-hosting should not mean building everything from scratch. That is why Dograh exists.
Dograh is an open source platform for voice bots and AI calling agents:
- Drag-and-drop workflow builder
- Build workflows in plain English
- Bring-your-own telephony, STT, LLM, and TTS
- Cloud-hosted or self-hosted
- The platform is multilingual and support multiple voices upto 30 languages
- Mid call language switching
- Multi-agent workflows to reduce hallucinations and enforce decision paths
- Website widget deployment enhance user experience
- A testing suite in progress (Looptalk) to stress test agents with simulated personas
If you want an open source alternative to hosted platforms, but you still want a fast setup, start with Dograh. I am looking for beta users and contributors because the fastest way to make this stronger is feedback from real call flows.
Final takeaway
Hosted platforms are the right move for most teams at the start, and Retell is one of the fastest ways to get to production.
If you have compliance constraints, need tighter control of data flow, or you are paying for enough minutes that platform markup is becoming a line-item you feel, move to self-hosting. At that point, the operational burden is worth it because you stop paying a platform tax on every call.
Use the formulas and tables above, plug in your numbers, and decide with a spreadsheet instead of gut feel.
Related Blog
- Discover the Self-Hosted Voice Agents vs Vapi : Real Cost Analysis
- A Practical Cost Comparison Self-Hosted Voice Agents vs Bland: Real Cost Analysis (100k+ Minute TCO)
- A Practical Cost Comparison Self-Hosted Voice Agents vs Bolna AI: Real Cost Analysis (DPDP-Safe TCO)
- Explore Voice AI for Law Firms: Why We Chose Quality Over Latency By Alejo Pijuan (Co-Founder & CEO @ Amplify Voice AI, AI Ethics Thought Leader, Expert Data Scientist, Previously senior data scientist at Nike.)
- See how 24/7 Virtual Receptionist Helps Small Firms Win More Clients by boosting responsiveness and improving customer engagement.
- Learn how From Copilots to Autopilots The Quiet Shift Toward AI Co-Workers By Prabakaran Murugaiah (Building AI Coworkers for Entreprises, Government and regulated industries.)
- Check out "An Year of Building Agents: My Workflow, AI Limits, Gaps In Voice AI and Self hosting" By Stephanie Hiewobea-Nyarko (AI Product Manager (Telus AI Factory), AI Coach, Educator and AI Consultancy)
FAQ's
1. Why does Retell feel cheaper at the beginning?
Retell reduces setup time, hides infrastructure complexity, and has optimized defaults. For MVPs and early launches, speed and reliability usually matter more than per-minute savings.
2. Is Retell pricing really just per minute?
No. Per-minute pricing is only part of the bill. STT, TTS, LLM usage, telephony, outbound call fees, and branded calls can significantly increase real-world costs.
3. Why does concurrency matter so much in voice AI costs?
Concurrency determines how many calls run at once. Higher concurrency increases infrastructure needs and can push you into higher pricing tiers. It’s one of the fastest ways for bills to spike unexpectedly.
4. What costs do teams usually miss when comparing voice platforms?
Common misses include engineering, on-call time, observability, call-recording storage, load testing for concurrency spikes, and compliance or vendor security reviews.
5. Why does latency matter more in voice than chat?
In voice, even a few seconds of silence feels broken. High first-response latency immediately damages trust, especially at the start of a call. Users forgive small delays later, but not a slow start.
6. Can self-hosted voice agents really go below $0.02 per minute?
Yes, but only with advanced setups. This usually requires self-hosting models, careful GPU scheduling, quantization, and strong ops discipline. It’s not recommended early because complexity and failure risk are high.
Was this article helpful?
