You are not choosing a "voice bot." You are choosing a full voice stack with ongoing bills and operational responsibility. This post helps you estimate the real monthly cost and the DPDP (Digital Personal Data Protection Act 2023) driven risk of two paths: self-hosting (Dograh AI + OSS building blocks) vs using Bolna AI using cost model comparison, scenario tables, and the cost multipliers most teams miss.


What this post will help you decide
You will leave with a realistic monthly cost range, not a marketing number. You will also understand where DPDP (India's privacy law) changes architecture choices. And users will also know which path fits his/her minutes, team size, and compliance bar.
Who this is for (India teams, devs, compliance-led orgs)
This is for Indian startups, product teams and compliance-led orgs building AI calling agents for support, collections, verification, or appointment workflows. It is also for developers comparing self-hosted voice agents (Dograh AI, LiveKit, Pipecat, Vocode style stacks) vs a managed platform like Bolna.
I am writing this from the perspective of building and evaluating self-hosted voice stacks, where something "works in a demo" often becomes "expensive in production."
What "real cost" means (not per-minute pricing)
Your total monthly bill is not a single per-minute number. It is a stack:
- Telephony (inbound/outbound minutes)
- STT (speech-to-text)
- LLM (tokens)
- TTS (text-to-speech)
- Platform fee (if using a managed platform)
- Hosting (CPU/GPU + bandwidth + load balancers)
- Engineering + on-call (deployment, scaling, fixes)
- Monitoring + logging
- Failure overhead (retries, timeouts, silence, fallbacks)
That is the model used throughout this post.
Quick definitions: self-hosted vs cloud vs OSS
Self-hosted means you run the voice agent runtime (and sometimes parts of STT/TTS) in your own cloud or servers, control logs and storage, and manage scaling. Cloud-managed means a vendor runs the agent platform and you pay usage, plus sometimes separate provider bills. OSS (open source) means the code is inspectable and modifiable, and you can deploy it yourself.
Where Bolna fits today: Bolna is a managed platform (not open source) with a strong India market focus and Indian language positioning. Pricing is usage-based and plan-based via its pricing page.

Table of Contents
- Myths to Ignore before you Compare Costs
- Cost components you actually pay for (full stack view)
- Scenario-based real cost analysis (10k, 50k, 100k, 500k minutes/month)
- Sensitivity analysis: what moves your bill the most
- Feature and architecture comparison (beyond cost)
- Decision guide: what to choose based on your situation
- What is token inflation in voice calls (and Why it spikes LLM cost)?
- FAQ
Myths to ignore before you compare costs
Skipping these myths saves you weeks of wrong spreadsheet math. Most teams lose money because they compare only headline per-minute pricing. Voice agents are a chain of vendors, latency constraints, and operational realities.
Myth 1: "Per-minute price is the total price"
A platform's per-minute number rarely includes everything. Even when it does, you still pay for waste: silence, retries, and long prompts.
Example: If your agent speaks slowly, you pay more TTS characters. If prompts are too long, you pay more LLM tokens. If you mis-handle turn-taking, users pay for dead silence.
Myth 2: "Self-hosted is always cheaper"
Self-hosting can be cheaper at high volume (<10k mins), but it is often not cheaper at low volume. If you do not have an ops owner, or you need reliability fast, managed platforms are often the better first step.
Self-hosting wins when you have:
- High minutes (<10k+)
- Strong compliance needs
- Need for custom routing, custom tools, or special logging controls
Self-hosting loses when you have:
- Low minutes
- No on-call readiness
- No time to tune latency and streaming reliability
Myth 3: "If a vendor is compliant, you're done" (DPDP reality)
Under India's DPDP Act (Digital Personal Data Protection), your company still owns accountability as a Data Fiduciary. Vendor compliance helps, but it does not remove your burden.
In practice, DPDP pushes you to have:
- Vendor due diligence and contracts
- Continuous oversight
- Data deletion workflows and consent withdrawal handling
- Clear retention rules and access control
Self-hosting can reduce risk by removing one vendor layer from the call path.
Glossary (key terms)
- DPDP Act (Digital Personal Data Protection Act, 2023): India's privacy law governing processing of personal data. It formalizes user rights and compliance obligations, with penalties for non-compliance.
- Data Fiduciary: The entity (usually your company) deciding why and how personal data is processed. Under DPDP, the Data Fiduciary remains responsible even when vendors process data.
- Latency budget (for streaming voice agents): The maximum acceptable end-to-end delay (speech -> text -> reasoning -> audio) before callers feel the agent is slow or broken. Smaller latency budgets often force more infrastructure headroom and higher cost.
- Turn detection (end-of-utterance detection): Logic that decides when the user is done speaking. Bad turn detection causes interruptions, extra retries, and wasted minutes.
- Reserved instances (commit pricing for self-hosted scaling): Cloud pricing discounts when you commit to capacity. This can materially lower per-minute hosting cost at 100k+ minutes, but reduces flexibility.
Cost components you actually pay for (full stack view)
Every voice agent cost is a sum of providers and operations. This section breaks the stack into invoice-ready buckets.
Per-minute voice stack costs (telephony + STT + LLM + TTS)
A typical real-time voice call includes:
- Telephony (PSTN minutes) Telephony is often a fixed per-minute cost. For Twilio, call costs are commonly in the range $0.0085-$0.022 per minute depending on geography and call type.
- STT (speech-to-text) Common reference prices (published comparisons):
1. OpenAI STT: $0.006
2. Google Cloud STT: $0.016 (and $0.004 at volume in some contexts)
3. AWS STT: ~ $0.024
- LLM (tokens) LLM cost depends on tokens per minute. Tokens increase with long system prompts, verbose agent replies, and retries.
- TTS (text-to-speech) Common reference prices (published comparisons):
1. OpenAI TTS: $0.015
2. Google Cloud TTS: ~ $0.016
3. AWS TTS: ~ $0.016
Practical note: these numbers are components, not your final price. Your final cost depends on your call flow, language, and tuning.
Platform fees vs provider bills (what gets double-counted)
Managed platforms often charge:
- A platform fee per minute
- Plus pass-through (or marked-up) provider costs
- Or "bring your own keys" where you pay providers directly
Bolna is explicit here: it offers a flat $0.02 per minute platform fee, plus STT, LLM, TTS, and telephony costs from providers you select, typically totaling $0.06-$0.10 per minute in examples.
Bolna also shows an example that reaches $0.102/min using:
- OpenAI GPT-4.1 Mini: $0.009/min
- ElevenLabs Turbo v2.5 TTS: $0.050/min
- Deepgram Nova 3 STT: $0.0092/min
- Twilio telephony: $0.014/min
- Bolna platform fee: $0.02/min
Invoice audit checklist (use this every month):
- Do you pay telephony to the platform, or directly to Twilio/telephony vendors?
- Do you pay STT/TTS to the platform, or directly to providers?
- Are there markups on tokens or characters?
- Is recording storage billed separately?
- Are failed minutes billed (timeouts, retries)?
- Are concurrency limits forcing you into higher plans?
Hosting and scaling costs for self-hosting (CPU/GPU + networking)
Self-hosting means you host some combination of:
- Agent orchestration and workflow engine
- Real-time streaming media
- Turn detection and barge-in logic
- Provider adapters (STT/LLM/TTS)
- Logs, call recordings, and analytics
- Observability (metrics + traces)
Tools and patterns that show up often:
- LiveKit for real-time media transport and conferencing primitives
- Pipecat or similar runtime patterns for streaming pipelines
- Vocode-style agent runtime patterns for voice loops
This is also where performance reality matters. If you plan to self-host STT with Whisper variants, you must understand GPU vs CPU behavior. Benchmarks show OpenAI Whisper Large V3 can hit 5-8% WER on clean English speech benchmarks, and performance scales dramatically with GPUs: RTF can exceed 100x on modern GPUs, but can drop below 1x on CPU for larger models.
Translation: self-hosting STT can be excellent, but CPU-only can become non-real-time for larger models, forcing GPUs or smaller models.
Engineering time, on-call, monitoring, and incident cost (ops line item)
Ops is a real cost line item. If you ignore it, self-hosted TCO will look artificially low.
Common overhead categories:
- Initial setup (infra + CI/CD + secrets + VPC)
- Scaling and load testing
- On-call / incident response
- Upgrades and regression testing
- Security reviews and access controls
- Monitoring: logs, metrics, traces, alerts
- Failure handling: retries, fallbacks, queueing
A simple estimation method:
Ops cost per month = (engineer hourly rate) x (hours per month on voice stack) Even 15-25 hours/month becomes significant when you are running production voice.
The cost of model (with assumptions table)
Use this model to compute your monthly cost in 10 minutes. It works for both managed platforms and self-hosted stacks. Then you can adjust with measured inputs from real calls.
Cost formula readers and (monthly total)
Monthly Total Cost:
Total = Telephony + STT + LLM + TTS + Platform Fees + Hosting + Engineer/On-call + Monitoring + Failure Overhead
Where:
- Telephony = minutes x telephony rate
- STT = minutes x stt rate
- TTS = minutes x tts rate (or characters x price/char)
- LLM = (tokens in x price/token) + (tokens out x price/token)
- Failure Overhead = Total x (waste%) Waste% includes silence, retries, timeouts, and re-prompts.
Assumptions table (models, tokens/min, chars/min, instance types)
These are starting assumptions. You must measure and update them. But you need a baseline to compare self-hosted vs Bolna. I include the anchor guidance requested for 10k and 100k+ minutes.
Important: if you plan to self-host STT, remember Whisper GPU vs CPU behavior. CPU can fall below real time for large models.
What you must measure in your own calls (inputs that change the bill)
Measure these before you commit to a cost target:
- Talk time vs silence time (silence is paid telephony time)
- Retry rate (timeouts, provider errors)
- Barge-in rate (users interrupting TTS)
- Language mix (Indian languages, code-mix)
- Average call length distribution (p50, p90)
- Human handoff rate (and where it happens)
- Tokens per minute (actual)
- Prompt length drift (system prompt growth)
Scenario-based real cost analysis (10k, 50k, 100k, 500k minutes/month)
This section converts the model into decision-ready numbers. These are ranges because vendor choices and tuning vary. The winner-by-volume pattern is usually consistent.
Scenario table: total monthly cost ranges (self-hosted vs Bolna)
Assumptions used:
- Telephony: $0.014/min (matches the Bolna example line item)
- STT: $0.0092/min (matches Bolna example line item)
- LLM+TTS combined anchor:
1. 10k mins: $0.085/min midpoint (given 8-9 cents/min guidance)
2. 50k mins: $0.070/min midpoint
3. 100k+ mins: $0.050/min or lower midpoint (given guidance)
- Bolna platform fee: $0.02/min
- Self-hosted platform software: $0 license (Dograh is open source), but user need to pay hosting + ops
- Hosting and ops are estimates, shown as ranges
Note: Bolna also offers plans like Explore (5,000 mins at 7 cents/min, $350/mo) and mentions concurrency ranges (20-75) in higher tiers. Plan pricing can beat PayG if your usage fits the tier, but concurrency limits can force upgrades.
At around 10k minutes, Bolna is likely the better choice due to faster setup and lower operational overhead. It works well when speed and simplicity matter more than deep control.
At about 50k minutes, a mix review of (Self-hosted setup and Bolna AI) usually works best. The right choice depends on your operational maturity and ability to manage infrastructure.
Choose self-hosting when compliance needs are strict or deep customization is required. It gives you more control.
Self-hosting wins where margins and control matter most. It gives you flexibility and long-term cost leverage.
How to read this table:
- Bolna adds a predictable $0.02/min platform fee.
- Self-hosting removes platform fees, but you pay hosting and ops.
- At very high minutes, self-hosting usually wins on unit economics and control, if your ops is stable.
Simple math walkthrough (10k minutes example)
Use this approach with your measured inputs. I will show both Bolna-style and self-hosted-style totals.
Assume 10,000 minutes/month.
- LLM + TTS combined Given guidance: at 10k minutes, combined TTS+LLM is around $0.08-$0.09/min. Use midpoint $0.085/min > 10,000 x 0.085 = $850
- STT Use the Bolna example STT number $0.0092/min. 10,000 x 0.0092 = $92
(For context: published STT references include OpenAI $0.006, Google $0.016, AWS ~ $0.024.)
- Telephony Use the Bolna example telephony number $0.014/min. 10,000 x 0.014 = $140
(For context: Twilio can range $0.0085-$0.022/min by geography.)
- Platform fee (Bolna path only) Bolna fee: $0.02/min. 10,000 x 0.02 = $200
Bolna-style subtotal = 850 + 92 + 140 + 200 = $1,282/month
Self-hosted-style subtotal (no platform fee) = 850 + 92 + 140 = $1,082/month
Then add:
- Hosting (agent runtime, media, observability): $200-$800
- Ops/engineering: $500-$3,000 Self-hosted total becomes $1,800-$4,900, depending on team maturity.
This is why self-hosted is not automatically cheaper at 10k minutes.
Volume discounts and optimization paths (what changes at 100k+ minutes)
At higher volume, small changes become large savings. This is where self-hosting starts to make unit economics sense. It is also where reserved instances and architecture tuning pay off.
Given guidance: at 100k+ minutes, combined TTS + LLM can be ~ $0.05/min or lower with planning.
How teams get there:
- Prompt trimming: shorter system prompts, smaller tool schemas
- Token controls: caps, structured outputs, shorter confirmations
- Cheaper model routing: small model for routine turns, larger model only for edge cases
- TTS tuning: faster speaking rate, fewer filler phrases, reduce repeated confirmations
- Caching: reuse standard responses, reuse policy disclosures
- Fallback design: avoid repeating whole prompts on retries
- Reserved instances for steady traffic to cut hosting cost (commit pricing)
If you plan to self-host STT, do not guess hardware. Whisper performance depends heavily on GPU vs CPU. CPU can fall below real-time for larger models.

Vapi vs Open Source Voice Agents: Which to Choose?
Discover Vapi vs Open-Source voice agents like Dograh, Pipecat, LiveKit, and Vocode to decide the best option for cost, control, and scale.
Sensitivity analysis: what moves your bill the most
Most voice cost spikes come from controllable behavior. Tokens, TTS verbosity, silence, and retries are the big ones. This section shows which knobs matter first.
Top cost drivers ranked (LLM tokens, TTS chars, silence, retries)
Ranked by typical impact:
- LLM tokens per minute If tokens/min increases by 20%, LLM cost follows almost linearly. Token growth happens when prompts grow, when you repeat instructions, and when retries replay context.
- TTS characters per minute If the agent speaks 15% more, you pay 15% more TTS. Many teams accidentally ship chatty agents that waste minutes and sound unnatural.
- Silence and turn detection errors Bad turn detection inflates telephony time and also triggers retries. This is paid time with zero value.
- Retries and fallbacks Provider timeouts cause repeated STT/LLM/TTS calls. One retry loop can double cost for that call.
Practical measurement:
- Track tokens/min, chars/min, silence%, retry%, and handoff% in logs.
Latency and reliability overhead (retries, timeouts, failover)
Latency is a cost input, not just a UX metric. To hit a tight latency budget, you keep more warm capacity online. That increases hosting cost.
Real-time stacks also need:
- Headroom for peak concurrency
- Stable networking
- Load testing for media paths
- Fallback providers for STT/TTS if one degrades
If you are self-hosting, tools like LiveKit help with media, but you still must tune it and observe it under load.
A real-world signal: builders often start self-hosted, then switch to a managed tier when scaling becomes painful, or use a hybrid approach. A Reddit thread on self-hosting suggests LiveKit is "simple to run" via Docker, but scaling decisions change over time and cloud tiers can be generous.
Compliance and privacy overhead (DPDP-driven choices)
DPDP changes both technical design and vendor strategy. It pushes you toward data minimization, retention limits, and controlled access. It also increases the cost of vendor oversight.
DPDP-driven requirements that often create work:
- Data minimization and purpose limitation
- Retention limits (automatic deletion)
- Audit logs for access and exports
- Consent withdrawal flows
- Deletion requests across vendors
- Contractual terms and security diligence for processors
Cost impact:
- Legal review time
- Engineering time for deletion pipelines and logging controls
- Ongoing audit overhead
My view: if you operate in fintech or healthtech, self-hosting is usually worth serious consideration even before you hit massive volume. Fewer external processors makes deletion, access control, and incident response simpler.
Synthflow vs Open Source Voice Agents: Which to Choose ?
Explore Synthflow vs Open-Source voice agents like Dograh, Pipecat, LiveKit, and Vocode to find the best option for cost, control, and scalability.
Feature and architecture comparison (beyond cost)
Cost is not the only axis. Architecture, control, and compliance readiness matter. This section compares what you can actually build and operate.
Customization and control (bring-your-own models and routing)
Self-hosted stacks are strongest when you need control:
- Swap STT providers by language or accent
- Route LLM calls by intent (cheap model for common flows)
- Control prompt templates per workflow
- Add your own tools and internal APIs via webhooks
- Build policy enforcement and guardrails
Dograh AI fits this model: it is an open-source platform focused on building inbound and outbound voice agents quickly using a drag-and-drop workflow builder, bring-your-own keys, and webhooks. It is designed to stay FOSS and self-hostable. You can learn more from the Dograh AI site.
It also supports a reliability pattern that I like for production: multi-agent workflows (decision-tree routing) where smaller specialized agents handle narrow steps, and you avoid one giant prompt doing everything.
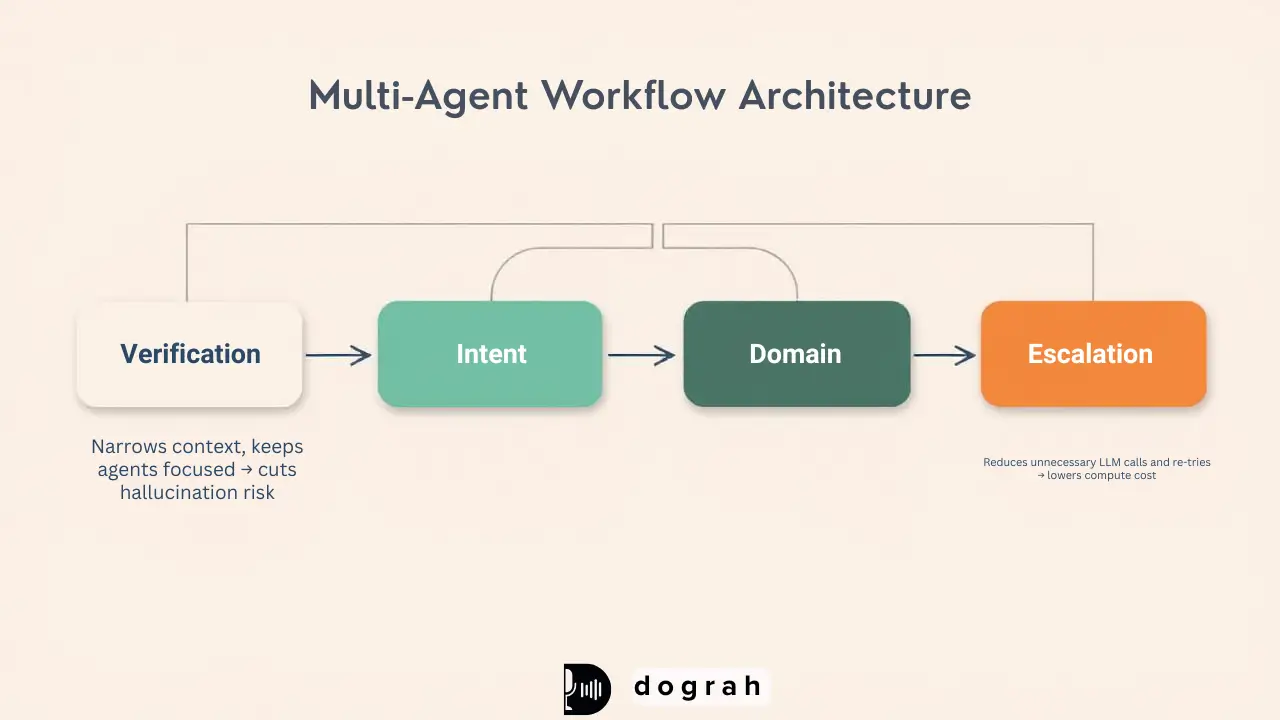
What is a multi-agent workflow (decision-tree routing) for voice bots?
A multi-agent workflow breaks one large agent into smaller agents, each with a single job. Instead of one model doing everything, the call moves through a flow like verification → intent detection → domain handling → escalation.
This reduces hallucinations because each agent has a smaller scope and fewer tools. It can also reduce cost because many turns can use cheaper models and shorter prompts, while only complex steps use heavier reasoning.
In Dograh, this maps naturally to a workflow: nodes for routing, tool calls, and fallback branches. It is about controlling failure modes and cost spikes.
India language and market fit (Bolna strengths vs OSS flexibility)
Bolna positions strongly for India-focused voice use cases and Indian languages. If you are launching fast for Indian customers, that focus can reduce setup time.
Self-hosted stacks can also support multilingual, but you must choose and test providers:
- STT accuracy for accents and code-mix
- TTS naturalness per language
- Latency differences by region
Recommendation: do a language bake-off with real calls before committing. Measure WER, fallback rates, and user interrupts.
Security and data residency: one less vendor layer vs vendor trust
Self-hosting changes the trust boundary. It reduces the number of third parties that handle raw audio, transcripts, and logs. This is often the simplest practical security win.
What is "one less hop" in a voice agent architecture?
"One less hop" means removing an extra vendor layer from the path between your customer's voice and your systems. In a managed platform flow, audio and transcripts often pass through the platform before hitting your tools or storage.
When you self-host, you can route the call from telephony -> your media/runtime -> your chosen STT/LLM/TTS providers, with your own logging and retention rules. You still may use external AI providers, but you reduce one processing layer and one set of logs outside your control.
For DPDP-sensitive teams, this matters because it reduces vendor exposure and simplifies deletion and access control.
Dev experience: build speed vs ops burden (tools list)
Managed platforms optimize for speed. Self-hosted optimizes for control. You are trading developer velocity against operational ownership. Be honest about your team's readiness.
Self-hosting is harder because you own:
- Deployment and upgrades
- Scaling and concurrency
- Streaming quality and latency
- Observability and tracing
- Security hardening and access controls
Common tools and building blocks:
- LiveKit for media transport
- Pipecat-style pipelines for streaming agents
- Vocode-like runtime patterns
- Monitoring stack (logs + metrics + alerts)
- Load testing and call simulation
From a practical builder perspective, a discussion from a developer building a voice agent and noting the tradeoffs: hosted gives "no deployment headache" but less control, while self-hosting often uses LiveKit or Pipecat.
Decision guide: what to choose based on your situation
Choose based on minutes, compliance pressure, and team capacity. Do not choose based on a demo. Choose based on TCO and DPDP posture. This section gives a rule-of-thumb decision.
Choose Bolna AI when (fast launch, low ops, lower minutes)
You are likely a good fit for Bolna when:
- You need to launch quickly with minimal engineering
- You are still validating the use case and prompts
- Your minutes are low or moderate (often <10k/month)
- You accept platform + vendor oversight processes
- You want a managed voice agent platform with a clear pricing structure Reference: Bolna's platform fee $0.02/min and example totals.
Choose self-hosted when (high minutes, strict compliance, custom stack)
You are likely a good fit for self-hosting when:
- You run 100k+ minutes/month and need margin control
- You need strict data control for fintech/healthtech
- You want one less vendor layer for logs, recordings, and PII control
- You need custom routing, multi-agent workflows, or internal toolchains
- You want to avoid platform lock-in and keep the system inspectable
If you want an open-source starting point with a workflow builder, evaluate Dograh AI as a self-hostable platform and adapt the stack to your preferred STT/LLM/TTS providers.

What is token inflation in voice calls (and Why it spikes LLM cost)?
Token inflation means your LLM consumes more tokens per minute than expected because context grows and repeats. In voice, this happens faster than chat because you have more turns, more filler phrases, and more failure paths.
Common causes:
- Long system prompts that keep expanding over time
- Re-sending the full conversation on retries
- Verbose confirmations ("Let me confirm that again...")
- Logging or tool outputs being fed back into the prompt
How to control it:
- Keep system prompts short and modular
- Summarize context every N turns
- Use structured tool outputs and strict schemas
- Do not replay full context on transient failures
This is one of the highest leverage optimizations you can make, because LLM cost tends to scale linearly with tokens.
Retell AI vs Open-Source Voice Agent Platforms: Which to choose ?
Compare Retell AI with Open-Source voice platforms like Dograh, Pipecat, LiveKit, and Vocode on cost, control, and scalability.
Prerequisites (so you do not break production calls)
These are required before serious comparison testing. Without them, your cost model will be wrong and your reliability will suffer. Treat this as the minimum bar for a pilot.
- Ability to measure minutes, tokens, chars, and retries
- A clear target for peak concurrency
- A decision on where recordings and transcripts are stored
- A DPDP-aligned retention policy (even if simple)
- An on-call owner (even if part-time) for voice incidents
Conclusion: the practical choice
At low minutes, managed platforms usually win on time-to-value because ops cost dominates. At high minutes, self-hosting can win on unit economics, control, and DPDP posture, if you can run the stack reliably.
If you want a DPDP-friendly architecture with maximum control, one less vendor layer is a real design advantage. If you want to launch quickly and learn fast, a managed platform is often the shortest path to production signals.
My recommendation:
- If you are below ~50k minutes/month and you do not have a clear on-call owner, use Bolna first and treat it as a paid benchmark.
- If you are above ~100k minutes/month or you handle sensitive PII under tight DPDP expectations, self-host and accept the ops work as the price of control.
If you are evaluating a self-hosted path, start by testing with an open source base like Dograh AI and measure tokens/min, chars/min, silence, and retries from day one.
Related Blog
- Discover the Self-Hosted Voice Agents vs Vapi : Real Cost Analysis
- A Practical Cost Comparison Self-Hosted Voice Agents vs Bland: Real Cost Analysis (100k+ Minute TCO)
- A Practical Cost Comparison Self-Hosted Voice Agents vs Retell: Real Cost Analysis (TCO Tables + $/Min).
- Explore Voice AI for Law Firms: Why We Chose Quality Over Latency By Alejo Pijuan (Co-Founder & CEO @ Amplify Voice AI, AI Ethics Thought Leader, Expert Data Scientist, Previously senior data scientist at Nike.)
- See how 24/7 Virtual Receptionist Helps Small Firms Win More Clients by boosting responsiveness and improving customer engagement.
- Learn how From Copilots to Autopilots The Quiet Shift Toward AI Co-Workers By Prabakaran Murugaiah (Building AI Coworkers for Entreprises, Government and regulated industries.)
- Check out "An Year of Building Agents: My Workflow, AI Limits, Gaps In Voice AI and Self hosting" By Stephanie Hiewobea-Nyarko (AI Product Manager (Telus AI Factory), AI Coach, Educator and AI Consultancy)
FAQ's
1. Is bolna.AI open source?
No. Bolna AI is a proprietary, fully managed platform, not open source. You use their hosted system rather than owning or modifying the core stack.
2. Is AI voice calling legal?
Yes, AI voice calling is legal in India, but it must be done with strict compliance and clear user consent. Under the DPDP Act (Digital Personal Data Protection Act, 2023), businesses are accountable as “Data Fiduciaries” for how personal data is collected, processed, stored, and shared with vendors.
3. How much do AI voice agents cost?
A realistic range is around 8-9 cents per minute at lower volumes, and closer to 5-6 cents per minute (or even ~5 cents) once you optimize prompts, use the right STT/TTS, and reach higher usage (like 100k minutes/month+).
4. How does the DPDP Act change the choice between self-hosted voice agents and managed platforms?
DPDP shifts the decision toward data control, not just cost. Since you remain responsible for personal data, self-hosted voice agents reduce vendor risk by keeping data, access, and audits inside your own cloud.
5. What should I check when evaluating a voice agent platform for India and Indian languages?
Check support for Indian accents and mixed languages, low-latency performance on local networks, and where voice data is processed under DPDP. Also verify speech accuracy, escalation handling, and audit controls.
Was this article helpful?
