Written By: Muyiwa (Moses) Ogundiya
Table of Contents
- Why Voice Agents Are Taking Off (And Why Buyers Get Excited)
- Africa and other Diverse language markets: What makes voice different
- Real Production Use Cases Seen in the Webinar
- Inbound + Outbound calling in one number (DID) and why it matters
- Key Technical Building Blocks (What Must Work)
- UX and Conversation Design: Where Voice Agents Win or Lose
- Where Voice Agents Break at Scale (And How to Prevent It)
- Automation Patterns That Make Voice Agents More Useful
- Cost and Tooling: Making Voice AI Affordable
- Conclusion
Building Voice Bots for Africa: Practical Guide to Affordable Voice AI
Voice AI is having a moment. But building voice bots for places like Nigeria is very different accents vary, languages are mixed, network quality is uneven, and user behavior is unpredictable. Tools made for “standard” environments don’t work well here. To succeed, voice systems must be built for real-world African conditions. The opportunity is massive, needing to match the engineering and UX discipline
When teams see a good voice agent demo for the first time, you can watch the shift happen. Their eyes light up, and the conversation moves from "is this real?" to "can it do this... and this... and this?"
I am going to share real-world lessons from deploying voice AI across African markets, what works, what breaks at scale, and how to build affordable, high-quality voice agents without sacrificing user experience. This article shares practical lessons from deploying voice AI at scale, including insights from the recent Detty December campaign.
Perfect for founders, engineers, and product teams building voice AI for emerging markets.
Why Voice Agents Are Taking Off (And Why Buyers Get Excited)
What is a voice agent ?
A voice agent (also called a voice bot or voice assistant for phone calls) is an AI system that can call people or receive calls, listen to what they say, and respond in natural speech like a human agent would.
Unlike text automation, voice feels personal and immediate, which is why teams deploying voice agents often see a dramatic shift from skepticism to excitement once they hear a working demo.
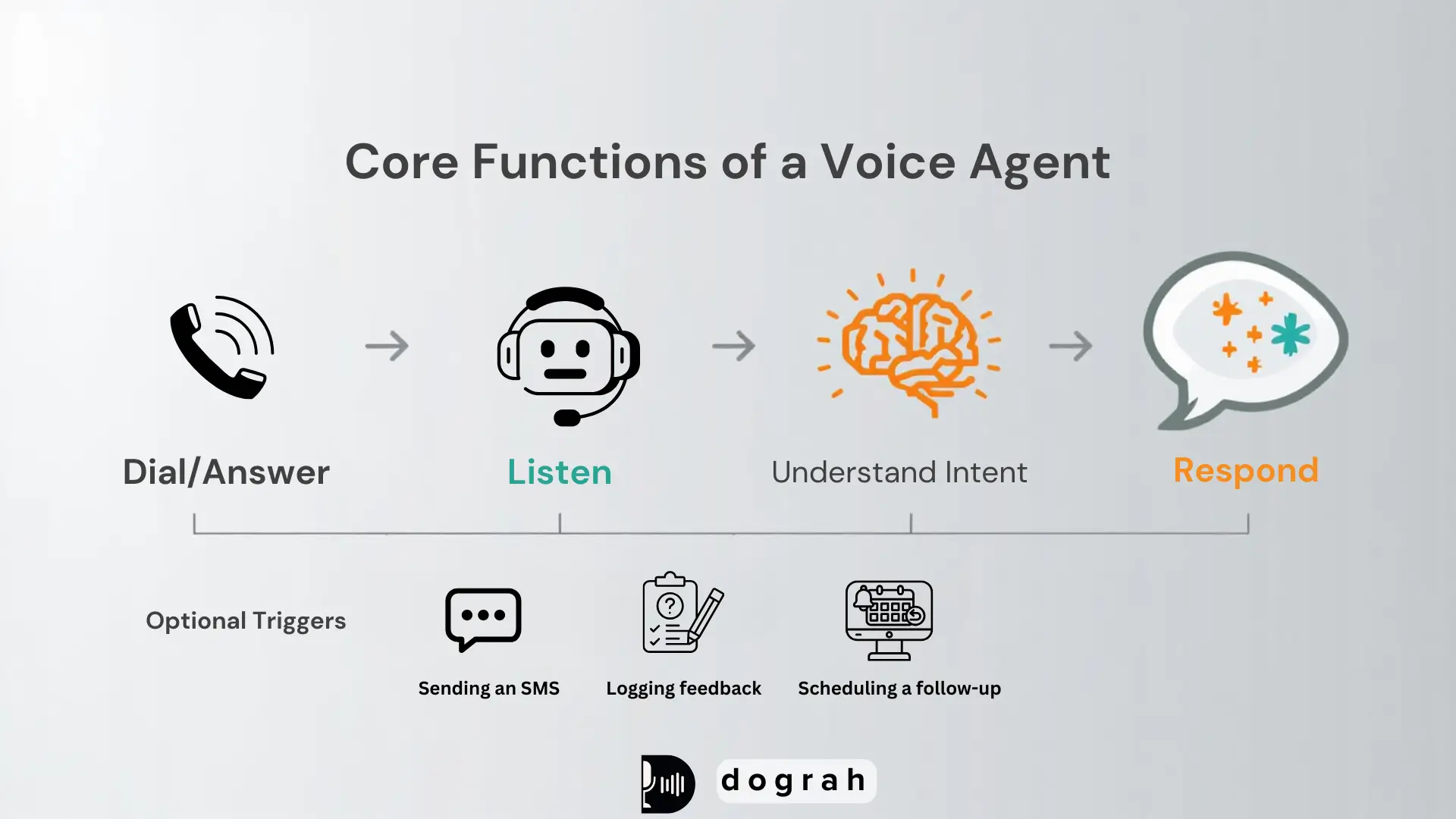
At a high level, a voice agent does four things:
- Dials (or answers) a phone call.
- Listens to the customer's speech.
- Understands intent and decides what to do next.
- Speaks back clearly, and (optionally) triggers actions like sending an SMS, logging feedback, or scheduling a follow-up.
When this works well, it feels like an efficient, polite call center agent that never gets tired.
Why enterprise teams want voice automation now
Enterprise teams want voice automation because it directly solves problems they already spend money on: outreach, customer support, verification, reminders, surveys, collections, and feedback.
Here are the biggest drivers I see:
- The demo effect ("wow" moment): Voice makes AI feel real immediately.
- Scale: Reaches thousands without scaling call centers
- Speed: Campaigns can go live quickly once the flow is stable.
- Customer experience: Improves customer experience with interactive conversations than email blasts.
- Automation ROI: Even small improvements in pickup rate or completion rate can justify the cost.
- Engagement : Drives higher engagement compared to SMS or email

Africa and other Diverse Language Markets: What Makes Voice Different

If you are building voice AI for Africa (Nigeria, Kenya, South Africa, Ghana, Egypt, etc.), you are not building a generic voice bot. You are building a system that has to survive:
Building voice AI for Africa is not a plug-and-play exercise. Key challenges include:
- Accents & code-switching: English blended with local languages, slang, Pidgin, and mixed cadence.
- Local place names & proper nouns: Popular models frequently falter on names like Ikeja, Surulere, or even Muyiwa, which harms credibility.
- Network variability & noise: Calls happen over patchy networks and in noisy environments.
- UX expectations: Africans often value clarity, brevity, and cultural relevance in voice interactions.
When a voice bot misunderstands a local term or mispronounces a familiar name, the user notices instantly, quickly breaking their trust.
One challenge I have faced repeatedly is local voice accuracy. Getting the right voices (and getting them to pronounce things correctly) is still hard.
I have seen TTS models mispronounce names constantly, including my name.
On the speech recognition side, many ASR systems struggle with Nigerian locations, terms, and the way we naturally blend words. That is not just a technical annoyance; it affects trust. If the bot cannot understand what someone said, or pronounces a local name wrong, the user feels it immediately.
Real Production Use Cases Seen in the Webinar
Outbound Detty December event invites at scale (RSVP + SMS follow-up)
One of the most reliable production use cases I have seen is event invitations, especially for organizations that already have large member lists.
I have run pilots, demos, and full campaigns where the client requests to call 5,000, 10,000, 20,000 people.
The workflow is simple, but effective:
- Upload a list of contacts
- The AI calls each person
- It invites them to an event
- It captures intent (interested / not interested / maybe)
- If they agree, it asks permission to send an SMS
- It sends event details (venue, time, ticket link)
The permission step is important. It’s always made explicit, users are asked and must agree before any additional actions, like sending SMS messages.
A real example: Lagos has a popular season of events (including "30 December" style campaigns). If you are selling tickets, voice outreach works because it is immediate and interactive.
FMCG feedback campaigns to schools (data-driven)
Another use case I like is voice-driven feedback collection for FMCG brands.
One scenario: an FMCG brand wants to reach school principals and heads of school to gather feedback about a children-focused product. Schools are a strong channel because that is where the children are, and many FMCG brands already run outreach programs.
Voice helps because:
- The audience is large and distributed
- The questions are structured
- You can collect feedback faster than manual calls
- You can standardize data capture (ratings, reasons, complaints)
This is where voice AI stops being a cool demo and starts doing real, useful work.
Fintech post-transaction feedback calls (tap-to-pay)
Fintechs move fast, and they care a lot about product feedback.
One of my favorite patterns is post-transaction feedback calls. For example, a fintech company launches a new tap-to-pay feature and wants to call customers shortly after they use it.
The flow looks like this:
1. Customer completes a payment
2. A trigger fires (webhook/event)
3. Within minutes, the AI calls:
- Thanks them
- Asks how the experience was
- Captures issues while the memory is fresh
As I explained it: The timing is the value. Feedback works best when you ask right away. If you wait too long, people forget the details.
Here are patterns we found effective, including from the Detty December outreach we carried out:
- Event Outreach at Scale: Use voice calls to invite audiences to events such as Detty December, it feels more personal, and when coupled with SMS follow-ups, improves RSVP rates.
The workflow includes: upload contact list > call > invite > capture interest > send details via SMS if permitted. - Feedback & Surveys: Voice AI works best for structured feedback, like after a transaction or product trial, where it can collect ratings and reasons much faster than manual calls.
- Post-Transaction Engagement: Trigger calls after key actions (e.g., ticket purchase) to collect impressions while they’re still fresh.
Inbound + Outbound calling in one number (DID) and why it matters
A surprisingly important detail is whether your system uses one phone number for both inbound and outbound calls.
Glossary: DID (Direct Inward Dialing)
A DID (Direct Inward Dialing) number is a phone number that can receive calls directly (often routed into VoIP systems). In voice agent systems, a DID can be configured to support outbound calls, inbound calls, or both.
In my implementation, I attach a DID to the AI so it can do both inbound and outbound. That sounds simple, but it changes UX and context.
Here is the nuance I learned the hard way:
- Outbound calls: The user often speaks first (they answer with "hello?").
- Inbound calls: The agent should speak first (the user expects a greeting).
In calls, who speaks first matters: outbound calls should let the user start, inbound calls should let the agent start, an often-overlooked detail.
There is also personalization context:
- Outbound: You can pass metadata ("Hi John...") because you initiated the call.
- Inbound: You may not know who is calling immediately, so you lose context
This matters for campaigns where people call you back after a missed call.
Key Technical Building Blocks (What Must Work)
Speech pipeline options: Speech-to-Speech vs STT > LLM > TTS
There are two common architectures for voice agents.
1. Speech-to-speech pipeline
- Audio in > model reasoning > audio out
- Can reduce complexity in some setups
2. STT > LLM > TTS pipeline
- speech-to-text (STT)
- large language model (LLM)
- text-to-speech (TTS)
What is an STT > LLM > TTS speech pipeline ?
An STT > LLM > TTS pipeline is a voice architecture where:
- STT (Speech-to-Text) converts the user's audio into text
- The LLM interprets the text and generates a response
- TTS (Text-to-Speech) converts the response text back into audio
This design is popular because each component can be swapped independently (better STT for accents, better TTS for voices, different LLM for cost/performance).
ASR and TTS quality for local languages and names
Glossary: ASR (Automatic Speech Recognition)
ASR converts spoken audio into text. When ASR fails, everything fails because the bot reasons over the wrong transcript.
Glossary: TTS (Text-to-Speech)
TTS converts text into spoken audio. When TTS is unnatural or mispronounces names and places, users lose trust fast.
In Nigeria, ASR often struggles with:
- Local place names
- Slang
- Code-switching
- Pronunciation variations
And TTS often struggles with:
- Nigerian names
- Stress patterns
- Natural pacing
I have said it plainly: If your bot cannot understand "Ikeja," "Yaba," "Surulere," or mispronounces "Muyiwa," it is not a minor defect. It is a credibility problem.
Latency, noise, and real-world audio conditions
Voice is real-time, so users notice even the smallest delay right away.
What is API latency in voice calls?
API latency in voice calls is the delay between:
- The user speaking, and
- The system processing that speech (STT + LLM + integrations), and
- The agent speaking back (TTS)
When latency is high, conversations feel awkward. People interrupt, think the call dropped, or hang up.
Here are the practical issues I plan for in production:
- Noisy environments: markets, roads, offices
- Interruption handling: user talks over the bot
- Silence detection: is the user thinking or gone?
- Turn-taking: avoiding awkward overlaps
- Network jitter: inconsistent audio quality
- End-of-call behavior: closing politely and cleanly
Key ingredients that must work well:
- Robust ASR/recognition for local accents
- Accurate TTS voices that get local names right
- Low latency for natural conversations
- Stable integration with telephony
UX and Conversation Design: Where Voice Agents Win or Lose
Most teams underestimate the work here.
My view: Voice agents are won and lost on UX.
Design for short, interactive calls (2-3 minutes)
A rule I live by: keep voice calls short.
Why?
- Longer calls increase user impatience
- The longer the call, the more likely the user realizes it is AI
- Once they know it is AI, many people try to break it
I have seen it repeatedly: "Anytime somebody finds out that they are talking to AI, they'll start asking all kinds of stupid questions, trying to break the AI."
So I aim for:
- 2-3 minutes max
- High interactivity
- Clear purpose
Conversation pacing: prompts that ask, wait, and confirm
I structure conversations with checkpoints.
A good pacing pattern:
1. Greeting + identity + check-in
- "Hi John, my name is X calling from Y. How are you today?"
2. Wait for a response
3. Permission to continue
- "Do you have a few seconds?"
4. Deliver the message in short chunks
5. Confirm next action
- "Would you like me to send details by SMS?"
6. Branching logic
- yes / no / unclear
Interaction requirements should be clear: the system shouldn’t just monologue, it must be designed to actively receive feedback.
Empathy and Sensitive moments (sickness, loss, bad days)
One of the most painful failures I have seen happened because the bot was not empathetic.
Bots must gracefully handle sensitive moments (illness, bad news, etc.), a brief empathetic response builds trust.
A user said they were not feeling well, and: "At that point, the AI... didn't demonstrate any empathy at all."
That is not a small issue. It can damage brand trust.
Here is my checklist of emotional edge cases you should account for:
- "I'm not feeling well."
- "I'm having a bad day."
- "I'm in a hospital."
- "I lost my job."
- "This is a bad time."
What the bot should do:
- Acknowledge briefly ("I'm sorry to hear that.")
- Offer a respectful exit ("I can call you another time.")
- Stop pushing the objective
- Log the outcome appropriately
Handling ambiguity without annoying repetition
Ambiguity is normal, especially with background noise.
My rule when speech is unclear:
- Ask for clarification once or twice
- If still unclear, fall back gracefully to to SMS or human follow-up if unclear after 1–2 tries
Fallback options include:
- Offer to send a short SMS link
- Schedule a call-back
- Hand off to a human (if available)
- End politely
When designing prompts, it’s important to ask for clarification once or twice if unsure, to ensure a smooth user experience.
Where Voice Agents Break at Scale (And How to Prevent It)
Prompt changes can cause big failures
One of the scariest realities in production is how one small prompt change can break a working system.
Even small, last-minute changes to a system prompt can cause the AI to break or behave unexpectedly, highlighting the importance of careful testing.
How I prevent this now:
- Treat prompts like code : Version them and test changes in staging
- Run regression tests on common edge cases
- Do not change prompts in a rush without a sanity test
Prompt engineering is real work, guiding AI to do what you want is challenging.
Outbound scaling issues: pick-up rates and retries
Outbound calling at scale introduces a basic truth: many people will not pick up.
If you call 200 people and only 50 pick up, you need a workflow for the 150 missed calls.
Implement a retry feature so missed interactions can be attempted again.
Also, pickup-rate behavior can be counterintuitive. In many campaigns, back-to-back calls from the same number can increase pickup rates (within reasonable limits and compliance).
Key best practices:
- Retry missed calls in controlled batches
- Vary timing (morning vs afternoon)
- Monitor spam labeling risk
- Respect opt-outs
Inbound vs Outbound flow mismatch and context loss
Inbound and outbound flows are not interchangeable.
- Outbound: user says "hello?" first, bot then greets
- Inbound: bot greets first and quickly orients the caller
Context loss is also real:
- Outbound: You can pass a template ("Hi Pritesh...") and personalize
- Inbound: the system may not know who is calling and why
If someone returns a missed call and the bot acts like it is still in outbound mode, the experience feels broken. Need to Merge context appropriately to avoid awkward flows.
Data capture challenges: phone numbers, emails, and sending SMS
Another production reality: LLMs can be unreliable with exact strings.
Common pain points:
- Users speak phone numbers too fast
- Background noise corrupts digits
- Emails are hard to capture accurately in voice
- Mapping the right number to the right follow-up action can fail
AI often struggles with handling numbers, like phone numbers or email addresses.
So I design around it:
- Prefer implicit identifiers (you already have the number you called)
- Confirm only when necessary ("I'll send it to this number ending in 1234, ok?")
- Request permission before SMS
- Keep a clean audit log of consent
Automation Patterns That Make Voice Agents More Useful
Call-back requests: tagging, metadata, and scheduling
Users often say: "call me back."
At scale, manual follow-up isn’t practical, so “call me back” should be handled as an automated trigger.
The pattern:
- Detect phrases like "call me back", "not now", "I'm busy"
- Attach metadata to that contact (e.g., callback_requested=true)
- Ask a quick follow-up: "What time should I call you back today?"
- Call an internal scheduling API
- Queue a future call attempt
If someone requests a callback, attach metadata to them and use it to schedule an automated follow-up through your system.
Guardrails I recommend:
- Do not schedule more than X retries per day
- Respect quiet hours
- Confirm time windows ("later today" -> offer options)
- If unclear, fall back to SMS
Event-driven voice workflows (from transactions to follow-ups)
The fintech example is part of a bigger pattern: event-driven voice.
If your business already emits events (payment complete, ticket purchased, appointment missed), you can trigger voice workflows automatically.
Why it works:
- It is contextual
- Timing is relevant
- You get higher-quality feedback
Typical triggers:
- Payment completed > feedback call
- Failed delivery > reschedule call
- Appointment booked > reminder call
- Subscription expiring > retention call
Choosing which edge cases to support first
Edge cases are endless.
I prioritize based on:
- Frequency: how often it happens
- Risk: how badly it can damage UX/trust
- Impact: does it affect conversion or completion rate?
- Complexity: can we ship a safe version quickly?
And I document what is out of scope, intentionally.
With many edge cases, it’s important to prioritize which ones matter most and which can be handled later.
Cost and Tooling: Making Voice AI Affordable
Why voice is expensive (the real cost drivers)
Voice AI is one of the most expensive AI application categories today.
The biggest cost drivers:
- TTS (speech generation): often the most expensive component
- Call duration: longer calls cost more
- Concurrency: more simultaneous calls = more compute
- Retries: missed calls and idle waiting multiply total minutes
- Latency overhead: inefficient pipelines increase billed usage
The main cost in a voice AI system comes from platform fees, speech synthesis and speech generation.
Cost control tactics: credits, model choices, and vendor mix
Here is what has helped me keep experiments and pilots affordable:
1. Use startup credits
- Take advantage of startup programs and free credits from platforms like Microsoft or AWS.
2. Compare vendors aggressively
- Some providers are great but costly
- Others are undervalued and perform well in specific regions
3. Mix providers by function
- Best ASR for your accent + affordable TTS + good LLM
- Self-host TTS where volumes justify it
4. Optimize UX to reduce minutes
- Keep calls 2-3 minutes
- Add early exits
- Avoid rambling prompts
Tools and models I have explored or tracked for affordability and value include:
- Kokoro (open-source options are improving fast)
- Qwen (strong model ecosystem)
- ElevenLabs (high quality, can be pricey)
- InWorld TTS (often surprisingly affordable)
- Region-specific providers (for India, for example, options like Sarvam)
The exact choice depends on language, voice quality needs, and deployment constraints.
Self-hosting TTS: when it makes sense
Self-hosting can reduce variable costs, especially if you have steady volume.
Hosted TTS pros:
- Easy to integrate
- Consistent quality
- Less ops burden
Hosted TTS cons:
- Can get expensive fast
- Less control over voice and latency
Self-hosted TTS pros:
- Lower marginal cost at scale
- More control (voices, tuning, caching)
Self-hosted TTS cons:
- GPU cost + maintenance
- Model updates and monitoring
- Engineering complexity
If you already have GPU capacity (or predictable high call volume), self-hosting starts to make sense.
Hosting your own text-to-speech models can provide a significant advantage.
Where open-source platforms can help
Open-source voice platforms help reduce total cost, especially engineering time and vendor lock-in.
Where open source helps most:
- Faster prototyping
- Flexible integrations
- Observability and debugging
- Customization for local market needs
My take: open source makes the build cheaper and more controllable, but execution still decides outcomes. If you do not invest in UX, testing, and consent flows, you will ship a bot that sounds good in a demo and fails on real calls.

Conclusion
Building voice bots for Africa is not "plug in a model and call it a day." The opportunity is massive especially when engineered for local complexities, from Detty December campaigns to feedback systems and post-transaction outreach. Success lies at the intersection of technical rigor, cultural relevance, and thoughtful UX design. When these pieces come together, voice bots don’t just automate tasks, they build connection, engagement, and measurable value across diverse markets.
Here is my stance after shipping these systems: if you cannot handle accents, names, noise, and retries, you should not launch a voice bot in Nigeria. The market will punish sloppy UX faster than any benchmark will.
Takeaways from what I have seen in production:
- Voice agents sell themselves in demos, but they survive in production through UX.
- Local language nuance is the battleground (ASR + TTS quality).
- Inbound vs outbound flows are different products, design them that way.
- Edge cases are endless, so prioritize ruthlessly.
- Costs are real, and TTS is usually the biggest lever.
If you get the UX right, keep calls short and respectful, and engineer for real-world African conditions (noise, accents, names, retries), you can build voice agents that deliver business results, not just a flashy demo.

FAQ’s
1. Why is building voice bots for Africa different?
African markets involve diverse accents, mixed languages, local names, and noisy environments that generic bots struggle with.
2. Why does accent and name pronunciation matter so much?
Mispronouncing local names or places immediately reduces trust and credibility.
3. What is the best time to collect feedback via voice?
Immediately after an event or transaction, while the experience is still fresh.
4. What is the recommended call length for voice agents?
Short calls—ideally 2 to 3 minutes-to keep users engaged and avoid frustration.
5. Why do voice agents fail at scale?
Small prompt changes, poor UX design, unhandled edge cases, and lack of testing can break systems.
6. How can teams reduce voice AI costs?
Use startup credits, keep calls short, mix vendors, and optimize UX to reduce call minutes.
7. When does self-hosting TTS make sense?
When you have steady call volume or existing GPU capacity and want lower long-term costs.
Was this article helpful?
